Smooks smooks = new Smooks("/smooks/echo-example.xml");
smooks.filterSource(new StreamSource(inputStream));.
Type Conversion
Number Decoding
Mapping Decoding
Enum Decoding
Other Definition Languages
Restrictions
Wildcard Bindings
Configuration
Example
Programmatic Configuration
Useful Regular Expressions
Options
User Guide
| This is the user guide for Smooks 2. For Smooks 1, visit the v1.7 user guide. |
Introduction
Smooks is an open-source, extensible Java framework for building event-driven applications that break up XML and non-XML data into chunks for data integration. It can be used as a lightweight framework on which to hook your own processing logic for a wide range of data formats but, out-of-the-box, Smooks ships with features that can be used individually or seamlessly together:
-
Java Binding: Populate POJOs from a source (CSV, EDI, XML, POJOs, etc…). Populated POJOs can either be the final result of a transformation, or serve as a bridge for further transformations like what is seen in template resources which generate textual results such as XML. Additionally, Smooks supports collections (maps and lists of typed data) that can be referenced from expression languages and templates.
-
Transformation: perform a wide range of data transformations and mappings. XML to XML, CSV to XML, EDI to XML, XML to EDI, XML to CSV, POJO to XML, POJO to EDI, POJO to CSV, etc…
-
Templating: extensible template-driven transformations, with support for XSLT, FreeMarker, and StringTemplate.
-
Scalable Processing: process huge payloads while keeping a small memory footprint. Split, transform and route fragments to JMS, filesystem, database, and other destinations.
-
Enrichment: enrich fragments with data from a database or other data sources.
-
Complex Fragment Validation: rule-based fragment validation.
-
Persistence: read fragments from, and save fragments to, a database with either JDBC, persistence frameworks (like MyBatis, Hibernate, or any JPA compatible framework), or DAOs.
-
Combine: leverage Smooks’s transformation, routing and persistence functionality for Extract Transform Load (ETL) operations.
-
Validation: perform basic or complex validation on fragment content. This is more than simple type/value-range validation.
Why Smooks?
Smooks was conceived to perform fragment-based transformations on messages. Supporting fragment-based transformation opened up the possibility of mixing and matching different technologies within the context of a single transformation. This meant that one could leverage distinct technologies for transforming fragments, depending on the type of transformation required by the fragment in question.
In the process of evolving this fragment-based transformation solution, it dawned on us that we were establishing a fragment-based processing paradigm. Concretely, a framework was being built for targeting custom visitor logic at message fragments. A visitor does not need to be restricted to transformation. A visitor could be implemented to apply all sorts of operations on fragments, and therefore, the message as a whole.
Smooks supports a wide range of data structures - XML, EDI, JSON, CSV, POJOs (POJO to POJO!). A pluggable reader interface allows you to plug in a reader implementation for any data format.
Fragment-Based Processing
The primary design goal of Smooks is to provide a framework that isolates and processes fragments in structured data (XML and non-XML) using existing data processing technologies (such as XSLT, plain vanilla Java, Groovy script).
A visitor targets a fragment with the visitor’s resource selector value. The targeted fragment can take in as much or as little of the source stream as you like. A fragment is identified by the name of the node enclosing the fragment. You can target the whole stream using the node name of the root node as the selector or through the reserved #document selector.
| The terms fragment and node denote different meanings. It is usually acceptable to use the terms interchangeably because the difference is subtle and, more often than not, irrelevant. A node may be the outer node of a fragment, excluding the child nodes. A fragment is the outer node and all its child nodes along with their character nodes (text, etc…). When a visitor targets a node, it typically means that the visitor can only process the fragment’s outer node as opposed to the fragment as a whole, that is, the outer node and its child nodes |
What’s new in Smooks 2?
Smooks 2 introduces the DFDL cartridge and revamps its EDI cartridge, while dropping support for Java 7 along with other notable changes:
-
DFDL cartridge
-
DFDL is a specification for describing file formats in XML. The DFDL cartridge leverages Apache Daffodil to parse files and unparse XML. This opens up Smooks to a wide array of data formats like SWIFT, ISO8583, HL7, and many more.
-
-
Added compatibility with Java 9 and later versions; retained compatibility for Java 8
-
-
Compose any series of transformations on an event outside the main execution context before directing the pipeline output to the execution result stream or to other destinations
-
-
Complete overhaul of the EDI cartridge and strengthening of EDI functionality
-
Rewritten to extend the DFDL cartridge and provide much better support for reading EDI documents
-
Added functionality to serialize EDI documents
-
As in previous Smooks versions, incorporated special support for EDIFACT
-
-
SAX NG filter
-
Replaces SAX filter and supersedes DOM filter
-
Brings with it a new visitor API which unifies the SAX and DOM visitor APIs
-
Cartridges migrated to SAX NG
-
Supports XSLT and StringTemplate resources unlike the legacy SAX filter
-
-
Mementos: a convenient way to stash and un-stash a visitor’s state during its execution lifecycle
-
Independent release cycles for all cartridges and one Maven BOM (bill of materials) to track them all
-
License change
-
After reaching consensus among our code contributors, we’ve dual-licensed Smooks under LGPL v3.0 and Apache License 2.0. This license change keeps Smooks open source while adopting a permissive stance to modifications.
-
-
New Smooks XSD schema (
xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd")-
Uniform XML namespace declarations: dropped
default-selector-namespaceandselector-namespaceXML attributes in favour of declaring namespaces within the standardxmlnsattribute from thesmooks-resource-configelement. -
Removed
default-selectorattribute fromsmooks-resource-configelement: selectors need to be set explicitly
-
-
Dropped Smooks-specific annotations in favour of JSR annotations
-
Farewell
@ConfigParam,@Config,@AppContext, and@StreamSinkWriter. Welcome@Inject. -
Farewell
@Initializeand@Uninitialize. Welcome@PostConstructand@PreDestroy.
-
-
Separate top-level Java namespaces for API and implementation to provide a cleaner and more intuitive package structure: API interfaces and internal classes were relocated to
org.smooks.apiandorg.smooks.enginerespectively -
Improved XPath support for resource selectors
-
Functions like
not()are now supported
-
-
Numerous dependency updates
-
Maven coordinates change: we are now publishing Smooks artifacts under Maven group IDs prefixed with
org.smooks -
Replaced default SAX parser implementation from Apache Xerces to FasterXML’s Woodstox: benchmarks consistently showed Woodstox outperforming Xerces
-
Monitoring and management support with JMX
Migrating from Smooks 1.7 to v2
Comparing the code examples for Smooks 1 with those for Smooks 2 can be a useful guide in migrating to Smooks 2. While not exhaustive, we have compiled a list of notes to assist your migration:
-
Smooks 2 no longer supports Java 7. Your application needs to be compiled to at least Java 8 to run Smooks 2.
-
Replace
javax.xml.transform.Sourceparameter inSmooks#filterSource(…)method calls with:-
org.smooks.io.source.JavaSourceinstead oforg.milyn.payload.JavaSource -
org.smooks.io.source.StringSourceinstead oforg.milyn.payload.StringSource -
org.smooks.io.source.ByteSourceinstead oforg.milyn.payload.ByteSource -
org.smooks.io.source.DOMSourceinstead oforg.milyn.payload.DOMSource -
org.smooks.io.source.JavaSourceWithoutEventStreaminstead oforg.milyn.payload.JavaSourceWithoutEventStream -
org.smooks.io.source.ReaderSourceinstead ofjavax.xml.transform.stream.StreamSourcewhen the latter is constructed fromjava.io.Reader -
org.smooks.io.source.StreamSourceinstead ofjavax.xml.transform.stream.StreamSourcewhen the latter is constructed fromjava.io.InputStream -
org.smooks.io.source.URLSourceinstead ofjavax.xml.transform.stream.StreamSourcewhen the latter is constructed from a system ID
-
-
Replace
javax.xml.transform.Resultparameter inSmooks#filterSource(…)method calls with:-
org.smooks.io.sink.StringSinkinstead oforg.milyn.payload.StringResult -
org.smooks.io.sink.JavaSinkinstead oforg.milyn.payload.JavaResult -
org.smooks.io.sink.ByteSinkinstead oforg.milyn.payload.ByteResult -
org.smooks.io.sink.DOMSinkinstead ofjavax.xml.transform.dom.DOMResult -
org.smooks.io.sink.StreamSinkinstead ofjavax.xml.transform.stream.StreamResultwhen the latter is constructed fromjava.io.OutputStream -
org.smooks.io.sink.WriterSinkinstead ofjavax.xml.transform.stream.StreamResultwhen the latter is constructed fromjava.io.Writer
-
-
Replace
closeResultattribute in the XML config elementcore:filterSettingswithcloseSink. -
Replace class interfaces:
-
org.milyn.delivery.ExecutionLifecycleInitializablewithorg.smooks.api.lifecycle.PreExecutionLifecycle -
org.milyn.delivery.ExecutionLifecycleCleanablewithorg.smooks.api.lifecycle.PostExecutionLifecycle -
org.milyn.delivery.VisitLifecycleCleanablewithorg.smooks.api.lifecycle.PostFragmentLifecycle -
org.milyn.delivery.ConfigurationExpanderwithorg.smooks.api.delivery.ResourceConfigExpander -
org.milyn.event.ResourceBasedEventwithorg.smooks.api.delivery.event.ResourceAwareEvent
-
-
Remove references to
org.milyn.util.CollectionsUtiland write your own implementation for this class. -
Implement from
org.smooks.api.resource.visitor.sax.ng.SaxNgVisitorinstead oforg.milyn.delivery.sax.SAXVisitor. -
Replace
Smooks#addConfiguration(…)method calls withSmooks#addResourceConfig(…). -
Replace
Smooks#addConfigurations(…)method calls withSmooks#addResourceConfigs(…). -
Replace references to:
-
org.milyn.javabean.DataDecodewithorg.smooks.api.converter.TypeConverterFactory. -
org.milyn.cdr.annotation.Configuratorwithorg.smooks.api.lifecycle.LifecycleManager. -
org.milyn.javabean.DataDecoderExceptionwithorg.smooks.api.converter.TypeConverterException. -
org.milyn.cdr.SmooksResourceConfigurationStorewithorg.smooks.api.Registry. -
org.milyn.cdr.SmooksResourceConfigurationwithorg.smooks.api.resource.config.ResourceConfig.-
Replace calls to
setDefaultResource()withsetSystem() -
Replace calls to
isDefaultResource()withisSystem()
-
-
org.milyn.delivery.sax.SAXToXMLWriterwithorg.smooks.io.DomSerializer. -
org.milyn.delivery.dom.serialize.Serializerreferences withorg.smooks.api.resource.visitor.SerializerVisitor -
org.milyn.event.types.ConfigBuilderEventreferences withorg.smooks.api.delivery.event.ContentDeliveryConfigExecutionEvent
-
-
Replace
org.milyn.*Java package references withorg.smooks.api,org.smooks.engine,org.smooks.ioororg.smooks.support. -
Change legacy document root fragment selectors from
$documentto#document. -
Remove the
milyn-smooks-alldependency from the Maven POM and import the Smooks BOM instead. Declare the corresponding dependency of each Smooks cartridge used within the project but omit the artifact version. -
Replace Smooks Maven coordinates to match the coordinates as described in the Maven guide.
-
Replace
ExecutionContext#isDefaultSerializationOn()method calls withExecutionContext#getContentDeliveryRuntime().getDeliveryConfig().isDefaultSerializationOn(). -
Replace
ExecutionContext#getContext()method calls withExecutionContext#getApplicationContext(). -
Replace
org.milyn.cdr.annotation.AppContextannotations withjavax.inject.Injectannotations. -
Replace
org.milyn.cdr.annotation.ConfigParamannotations withjavax.inject.Injectannotations:-
Substitute the
@ConfigParamname attribute with the@javax.inject.Namedannotation. -
Wrap
java.util.Optionalaround the field to mimic the behaviour of the@ConfigParamoptional attribute.
-
-
Replace
org.milyn.delivery.annotation.Initializeannotations withjakarta.annotation.PostConstructannotations. -
Replace
org.milyn.delivery.annotation.Uninitializeannotations withjakarta.annotation.PreDestroyannotations. -
Follow the EDIFACT-to-Java example to migrate an implementation that binds an EDIFACT document to a POJO.
-
Follow the Java-to-EDIFACT example to migrate an implementation that deserialises a POJO into an EDIFACT document.
-
Set
ContainerResourceLocatorfromDefaultApplicationContextBuilder#setResourceLocatorinstead fromApplicationContext#setResourceLocator.
FAQs
See the FAQ.
Maven
See the Maven guide for details on how to integrate Smooks into your project via Maven.
Fundamentals
A commonly accepted definition of Smooks is of it being a Transformation Engine. Nonetheless, at its core, Smooks makes no reference to data transformation. The core codebase is designed to hook visitor logic into an event stream produced from a source of some kind. As such, in its most distilled form, Smooks is a Structured Data Event Stream Processor.
An application of a structured data event processor is transformation. In implementation terms, a Smooks transformation solution is a visitor reading the event stream from a source to produce a different representation of the input. However, Smooks’s core capabilities enable much more than transformation. A range of other solutions can be implemented based on the fragment-based processing model:
-
Java binding: population of a POJO from the source.
-
splitting & routing: perform complex splitting and routing operations on the source stream, including routing data in different formats (XML, EDI, CSV, POJO, etc…) to multiple destinations concurrently.
-
huge message processing: declaratively consume (transform, or split and route) huge messages without writing boilerplate code.
The following gives a 10,000 foot view of Smooks:
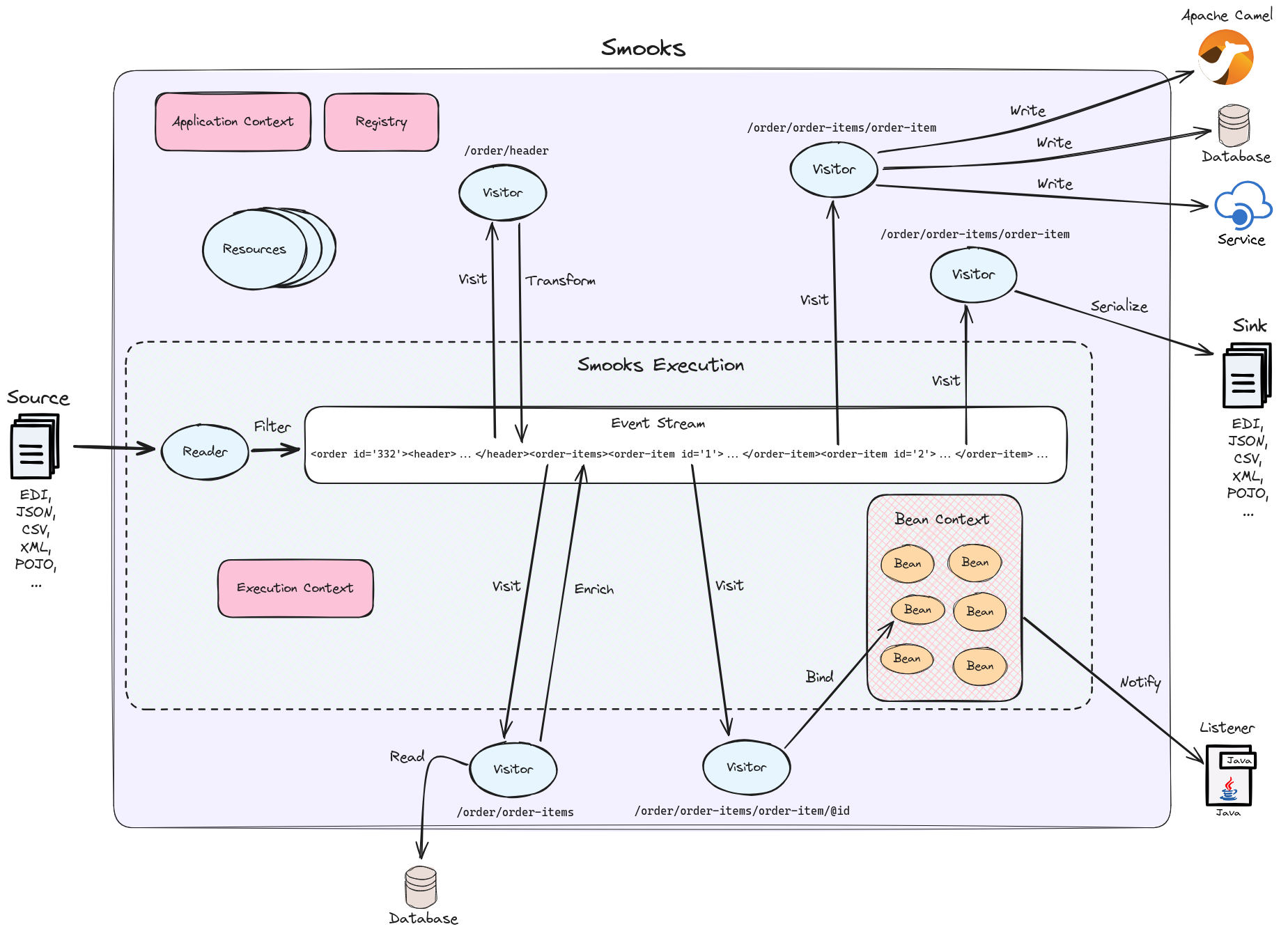
Smooks’s fundamental behaviour is to take an input source, such as CSV, and from it generate an event stream to which visitors are applied to produce a result, such as EDI. In Smooks nomenclature, this behaviour is called filtering. During filtering, you have other Smooks actors which are participating, including:
-
resources
-
application context
-
execution context
-
bean context
-
registry
-
listeners
All of these actors are explained in later sections. Several sources and result types are supported which equate to different transformation types, including but not limited to:
-
XML to XML
-
XML to POJO
-
POJO to XML
-
POJO to POJO
-
EDI to XML
-
EDI to POJO
-
POJO to EDI
-
CSV to XML
-
CSV to …
-
… to …
Smooks maps the source to the result with the help of a highly-tunable SAX event model. The hierarchical events generated from an XML source (startElement, endElement, etc…) drive the SAX event model though the event model can be just as easily applied to other structured data sources (EDI, CSV, POJO, etc…). The most important events are typically the before and after visit events. The following illustration conveys the hierarchical nature of these events:
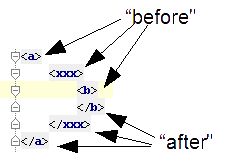
Hello World App
One or more of SaxNgVisitor interfaces need to be implemented in order to consume the SAX event stream produced from the source, depending on which events are of interest.
The following is a hello world app demonstrating how to implement a visitor that is fired on the visitBefore and visitAfter events of a targeted node in the event stream. In this case, Smooks configures the visitor to target element foo:

The visitor implementation is straightforward: one method implementation per event. As shown above, a Smooks config (more about resource-config later on) is written to target the visitor at a node’s visitBefore and visitAfter events.
The Java code executing the hello world app is a two-liner:
Observe that in this case the program does not produce a result. The program does not even interact with the filtering process in any way because it does not provide an ExecutionContext to smooks.filterSource(...).
This example illustrated the lower level mechanics of the Smooks’s programming model. In reality, most users are not going to want to solve their problems at this level of detail. Smooks ships with substantial pre-built functionality, that is, pre-built visitors. Visitors are bundled based on functionality: these bundles are called Cartridges.
Smooks Resources
A Smooks execution consumes an source of one form or another (XML, EDI, POJO, JSON, CSV, etc…), and from it, generates an event stream that fires different visitors (Java, Groovy, DFDL, XSLT, etc…). The goal of this process can be to produce a new result stream in a different format (data transformation), bind data from the source to POJOs and produce a populated Java object graph (Java binding), produce many fragments (splitting), and so on.
At its core, Smooks views visitors and other abstractions as resources. A resource is applied when a selector matches a node in the event stream. The generality of such a processing model can be daunting from a usability perspective because resources are not tied to a particular domain. To counteract this, Smooks 1.1 introduced an Extensible Configuration Model feature that allows specific resource types to be specified in the configuration using dedicated XSD namespaces of their own. Instead of having a generic resource config such as:
<resource-config selector="order-item">
<resource type="ftl"><!-- <item>
<id>${.vars["order-item"].@id}</id>
<productId>${.vars["order-item"].product}</productId>
<quantity>${.vars["order-item"].quantity}</quantity>
<price>${.vars["order-item"].price}</price>
</item>
-->
</resource>
</resource-config>an Extensible Configuration Model allows us to have a domain-specific resource config:
<ftl:freemarker applyOnElement="order-item">
<ftl:template><!-- <item>
<id>${.vars["order-item"].@id}</id>
<productId>${.vars["order-item"].product}</productId>
<quantity>${.vars["order-item"].quantity}</quantity>
<price>${.vars["order-item"].price}</price>
</item>
-->
</ftl:template>
</ftl:freemarker>When comparing the above snippets, the latter resource has:
-
A more strongly typed domain specific configuration and so is easier to read,
-
Auto-completion support from the user’s IDE because the Smooks 1.1+ configurations are XSD-based, and
-
No need set the resource type in its configuration.
Visitors
Central to how Smooks works is the concept of a visitor. A visitor is a Java class performing a specific task on the targeted fragment such as applying an XSLT script, binding fragment data to a POJO, validate fragments, etc…
Selectors
Resource selectors are another central concept in Smooks. A selector chooses the node/s a visitor should visit, as well working as a simple opaque lookup value for non-visitor logic.
When the resource is a visitor, Smooks will interpret the selector as an XPath-like expression. There are a number of things to be aware of:
-
The order in which the XPath expression is applied is the reverse of a normal order, like what hapens in an XSLT script. Smooks inspects backwards from the targeted fragment node, as opposed to forwards from the root node.
-
Not all of the XPath specification is supported. A selector supports the following XPath syntax:
-
text()and attribute value selectors:a/b[text() = 'abc'],a/b[text() = 123],a/b[@id = 'abc'],a/b[@id = 123].-
text()is only supported on the last selector step in an expression:a/b[text() = 'abc']is legal whilea/b[text() = 'abc']/cis illegal. -
text()is only supported on visitor implementations that implement theAfterVisitorinterface only. If the visitor implements theBeforeVisitororChildrenVisitorinterfaces, an error will result.
-
-
or&andlogical operations:a/b[text() = 'abc' and @id = 123],a/b[text() = 'abc' or @id = 123] -
Namespaces on both the elements and attributes:
a:order/b:address[@b:city = 'NY'].This requires the namespace prefix-to-URI mappings to be defined. A configuration error will result if not defined. Read the namespace declaration section for more details. -
Supports
=(equals),!=(not equals),<(less than),>(greater than). -
Index selectors:
a/b[3].
-
Namespace Declaration
The xmlns attribute is used to bind a selector prefix to a namespace:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:c="http://c" xmlns:d="http://d">
<resource-config selector="c:item[@c:code = '8655']/d:units[text() = 1]">
<resource>com.acme.visitors.MyCustomVisitorImpl</resource>
</resource-config>
</smooks-resource-list>Alternatively, namespace prefix-to-URI mappings can be declared using the legacy core config namespace element:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd">
<core:namespaces>
<core:namespace prefix="c" uri="http://c"/>
<core:namespace prefix="d" uri="http://d"/>
</core:namespaces>
<resource-config selector="c:item[@c:code = '8655']/d:units[text() = 1]">
<resource>com.acme.visitors.MyCustomVisitorImpl</resource>
</resource-config>
</smooks-resource-list>Input
Smooks relies on a Reader for ingesting a source and generating a SAX event stream. A reader is any class extending XMLReader. By default, Smooks uses the XMLReader returned from XMLReaderFactory.createXMLReader(). You can easily implement your own XMLReader to create a non-XML reader that generates the source event stream for Smooks to process:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<reader class="com.acme.ZZZZReader" />
<!--
Other Smooks resources, e.g. <jb:bean> configs for
binding data from the ZZZZ data stream into POJOs....
-->
</smooks-resource-list>The reader config element is referencing a user-defined XMLReader. It can be configured with a set of handlers, features and parameters:
<reader class="com.acme.ZZZZReader">
<handlers>
<handler class="com.X" />
<handler class="com.Y" />
</handlers>
<features>
<setOn feature="http://a" />
<setOn feature="http://b" />
<setOff feature="http://c" />
<setOff feature="http://d" />
</features>
<params>
<param name="param1">val1</param>
<param name="param2">val2</param>
</params>
</reader>Packaged Smooks modules, known as cartridges, provide support for non-XML readers but, by default, Smooks expects an XML source. Omit the class name from the reader element to set features on the default XML reader:
<reader>
<features>
<setOn feature="http://a" />
<setOn feature="http://b" />
<setOff feature="http://c" />
<setOff feature="http://d" />
</features>
</reader>Output
Smooks can present output to the outside world in two ways:
-
As instances of
Sink: client code extracts output from theSinkinstance after passing an empty one toSmooks#filterSource(...). -
As side effects: during filtering, resource output is sent to web services, local storage, queues, data stores, and other locations. Events trigger the routing of fragments to external endpoints such as what happens when splitting and routing.
Unless configured otherwise, a Smooks execution does not accumulate the input data to produce all the outputs. The reason is simple: performance! Consider a document consisting of hundreds of thousands (or millions) of orders that need to be split up and routed to different systems in different formats, based on different conditions. The only way of handing documents of these magnitudes is by streaming them.
| Smooks can generate output in either, or both, of the above ways, all in a single filtering pass of the source. It does not need to filter the source multiple times in order to generate multiple outputs, critical for performance. |
Sink
A look at the Smooks API reveals that Smooks can be supplied with multiple Sink instances:
public void filterSource(Source source, Sink... sinks) throws SmooksExceptionSmooks can work with implementation of StreamSink and DOMSink sink types, as well as:
-
JavaSink: sink type for capturing the contents of the Smooks JavaBean context. -
StringSink:StringSinkextension wrapping aStringWriter, useful for testing.
As yet, Smooks does not support capturing output to multiple Sink instances of the same type. For example, you can specify multiple StreamSink instances in Smooks.filterSource(...) but Smooks will only output to the first StreamSink instance.
|
Stream Sinks
The StreamSink and DOMSink types receive special attention from Smooks. When the default.serialization.on global parameter is turned on, which by default it is, Smooks serializes the stream of events to XML while filtering the source. The XML is fed to the Sink instance if a StreamSink or DOMSink is passed to Smooks#filterSource.
| This is the mechanism used to perform a standard 1-input/1-xml-output character-based transformation. |
Side Effects
Smooks is also able to generate different types of output during filtering, that is, while filtering the source event stream but before it reaches the end of the stream. A classic example of this output type is when it is used to split and route fragments to different endpoints for processing by other processes.
Pipeline
A pipeline is a flexible, yet simple, Smooks construct that isolates the processing of a targeted event from its main processing as well as from the processing of other pipelines. In practice, this means being able to compose any series of transformations on an event outside the main execution context before directing the pipeline output to the execution sink stream or to other destinations. With pipelines, you can enrich data, rename/remove nodes, and much more.
Under the hood, a pipeline is just another instance of Smooks, made self-evident from the Smooks config element declaring a pipeline:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd">
<core:smooks filterSourceOn="...">
<core:action>
...
</core:action>
<core:config>
<smooks-resource-list>
...
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>core:smooks fires a nested Smooks execution whenever an event in the stream matches the filterSourceOn selector. The pipeline within the inner smooks-resource-list element visits the selected event and its child events. It is worth highlighting that the inner smooks-resource-list element behaves identically to the outer one, and therefore, it accepts resources like visitors, readers, and even pipelines (a pipeline within a pipeline!). Moreover, a pipeline is transparent to its nested resources: a resource’s behaviour remains the same whether it’s declared inside a pipeline or outside it.
The optional core:action element tells the nested Smooks instance what to do with the pipeline’s output. The next sections list the supported actions.
Inline
Merges the pipeline’s output with the sink stream:
...
<core:action>
<core:inline>
...
</core:inline>
</core:action>
...As described in the subsequent sections, an inline action replaces, prepends, or appends content.
Replace
Substitutes the selected fragment with the pipeline output:
...
<core:inline>
<core:replace/>
</core:inline>
...Prepend Before
Adds the output before the selector start tag:
<core:inline>
<core:prepend-before/>
</core:inline>Prepend After
Adds the output after the selector start tag:
<core:inline>
<core:prepend-after/>
</core:inline>Append Before
Adds the output before the selector end tag:
<core:inline>
<core:append-before/>
</core:inline>Append After
Adds the output after the selector end tag:
<core:inline>
<core:append-after/>
</core:inline>Bind To
Binds the output to the execution context’s bean store:
...
<core:action>
<core:bindTo id="..."/>
</core:action>
...Output To
Directs the output to a different stream other than the sink stream:
...
<core:action>
<core:outputTo outputStreamResource="..."/>
</core:action>
...Rewrite
The core:rewrite construct is a reader designed to offer a convenient mechanism for substituting the event stream entering a pipeline with one that the pipeline resources can process.
core:rewrite enables one or more of its enclosed visitors to substitute targeted events with new events. In the example that follows, the pipeline feeds the event stream to core:rewrite, and core:rewrite in turn, feeds targeted events to the nested FreeMarker visitors:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.0.xsd"
xmlns:edifact="https://www.smooks.org/xsd/smooks/edifact-2.0.xsd">
...
...
<core:smooks filterSourceOn="#document">
<core:action>
<core:inline>
<core:replace/>
</core:inline>
</core:action>
<core:config>
<smooks-resource-list>
<core:rewrite>
<ftl:freemarker applyOnElement="#document" applyBefore="true">
<ftl:template>header.xml.ftl</ftl:template>
</ftl:freemarker>
<core:smooks filterSourceOn="record" maxNodeDepth="0">
<core:config>
<smooks-resource-list>
<ftl:freemarker applyOnElement="#document">
<ftl:template>body.xml.ftl</ftl:template>
</ftl:freemarker>
</smooks-resource-list>
</core:config>
</core:smooks>
<ftl:freemarker applyOnElement="#document">
<ftl:template>footer.xml.ftl</ftl:template>
</ftl:freemarker>
</core:rewrite>
<edifact:unparser schemaUri="/d96a/EDIFACT-Messages.dfdl.xsd" unparseOnNode="*">
<edifact:messageTypes>
<edifact:messageType>ORDERS</edifact:messageType>
</edifact:messageTypes>
</edifact:unparser>
</smooks-resource-list>
</core:config>
</core:smooks>
...
...
</smooks-resource-list>A visitor within core:rewrite writes XML fragments to the sink stream, replacing the targeted events. For example, in the config above, the FreeMarker visitors are replacing the #document and record events with materialised XML templates. More precisely, core:rewrite converts the materialised XML into a new event stream which is then processed by the downstream pipeline resources, in this case, edifact:unparser.
| The full example is available in the smooks-examples repository. |
When implementing your own visitor for core:rewrite, call org.smooks.io.Stream#out(org.smooks.api.ExecutionContext).write(java.lang.String) within one of the overridden visit methods to replace the event stream as shown below:
package org.smooks.benchmark;
...
...
public class BibliographyVisitor implements AfterVisitor {
private final static String TEMPLATE = "<entry><author>%s</author><title>%s</title></entry>";
private DOMXPath domXPath;
private DOMXPath titleXPath;
@PostConstruct
public void postConstruct() throws JaxenException {
this.domXPath = new DOMXPath("//author");
this.titleXPath = new DOMXPath("//title");
}
@Override
public void visitAfter(Element element, ExecutionContext executionContext) {
try {
List<Element> authors = ((List<Element>) domXPath.evaluate(element));
List<Element> titles = ((List<Element>) titleXPath.evaluate(element));
Stream.out(executionContext).write(String.format(TEMPLATE, authors.isEmpty() ? "N/A" : authors.get(0).getTextContent(), "<![CDATA[" + (titles.isEmpty() ? "N/A" : titles.get(0).getTextContent())) + "]]>");
} catch (IOException | JaxenException e) {
throw new SmooksException(e);
}
}
}BibliographyVisitor is a custom visitor which visits end events. The visitAfter method evaluates the author elements together with the title elements and writes XML to the sink stream replacing the selected events.
Cartridge
The basic functionality of Smooks can be extended through the development of a Smooks cartridge. A cartridge is a Java archive (JAR) containing reusable resources (also known as Content Handlers). A cartridge augments Smooks with support for a specific type input source or event handling.
Visit the GitHub repositories page for the complete list of Smooks cartridges.
Filter
A Smooks filter delivers generated events from a reader to the application’s resources. Smooks 1 had the DOM and SAX filters. The DOM filter was simple to use but kept all the events in memory while the SAX filter, though more complex, delivered the events in streaming fashion. Having two filter types meant two different visitor APIs and execution paths, with all the baggage it entailed.
Smooks 2 unifies the legacy DOM and SAX filters without sacrificing convenience or performance. The new SAX NG filter drops the API distinction between DOM and SAX. Instead, the filter streams SAX events as partial DOM elements to SAX NG visitors targeting the element. A SAX NG visitor can read the targeted node as well as any of the node’s ancestors but not the targeted node’s children or siblings in order to keep the memory footprint to a minimum.
The SAX NG filter can mimic DOM by setting its max.node.depth parameter to 0 (default value is 1), allowing each visitor to process the complete DOM tree in its visitAfter(...) method:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<params>
<param name="max.node.depth">0</param>
</params>
...
</smooks>A max.node.depth value of greater than 1 will tell the filter to read and keep an node’s descendants up to the desired depth. Take the following input as an example:
<order id="332">
<header>
<customer number="123">Joe</customer>
</header>
<order-items>
<order-item id="1">
<product>1</product>
<quantity>2</quantity>
<price>8.80</price>
</order-item>
<order-item id="2">
<product>2</product>
<quantity>2</quantity>
<price>8.80</price>
</order-item>
<order-item id="3">
<product>3</product>
<quantity>2</quantity>
<price>8.80</price>
</order-item>
</order-items>
</order>Along with the config:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<params>
<param name="max.node.depth">2</param>
</params>
<resource-config selector="order-item">
<resource>org.acme.MyVisitor</resource>
</resource-config>
</smooks>At any given time, there will always be a single order-item in memory containing product because max.node.depth is 2. Each new order-item overwrites the previous order-item to minimise the memory footprint. MyVisitor#visitAfter(...) is invoked 3 times, each invocation corresponding to an order-item fragment. The first invocation will process:
<order-item id='1'>
<product>2</product>
</order-item>While the second invocation will process:
<order-item id='2'>
<product>2</product>
</order-item>Whereas the last invocation will process:
<order-item id='3'>
<product>3</product>
</order-item>Programmatically, implementing org.smooks.api.resource.visitor.sax.ng.ParameterizedVisitor will give you fine-grained control over the visitor’s targeted element depth:
...
public class DomVisitor implements ParameterizedVisitor {
@Override
public void visitBefore(Element element, ExecutionContext executionContext) {
}
@Override
public void visitAfter(Element element, ExecutionContext executionContext) {
System.out.println("Element: " + XmlUtil.serialize(element, true));
}
@Override
public int getMaxNodeDepth() {
return Integer.MAX_VALUE;
}
}ParameterizedVisitor#getMaxNodeDepth() returns an integer denoting the targeted element’s maximum tree depth the visitor can accept in its visitAfter(...) method.
Settings
Filter-specific knobs are set through the smooks-core configuration namespace (https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd) introduced in Smooks 1.3:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd">
<core:filterSettings type="SAX NG" (1)
defaultSerialization="true" (2)
terminateOnException="true" (3)
closeSource="true" (4)
closeSink="true" (5)
rewriteEntities="true" (6)
readerPoolSize="3"/> (7)
<!-- Other visitor configs etc... -->
</smooks-resource-list>| 1 | type (default: SAX NG): the type of processing model that will be used. SAX NG is the recommended type. The DOM type is deprecated. |
| 2 | defaultSerialization (default: true): if default serialization should be switched on. Default serialization being turned on simply tells Smooks to locate a StreamSink (or DOMSink) in the Sink objects provided to the Smooks.filterSource method and to serialize all events to that Sink instance. This behavior can be turned off using this global configuration parameter and can be overridden on a per-fragment basis by targeting a visitor at that fragment that takes ownership of the org.smooks.io.FragmentWriter object. |
| 3 | terminateOnException (default: true): whether an exception should terminate execution. |
| 4 | closeSource (default: true): close InputStream instance streams passed to the Smooks.filterSource method. The exception here is System.in, which will never be closed. |
| 5 | closeSink: close Sink streams passed to the [Smooks.filterSource method (default "true"). The exception here is System.out and System.err, which will never be closed. |
| 6 | rewriteEntities: rewrite XML entities when reading and writing (default serialization) XML. |
| 7 | readerPoolSize: reader Pool Size (default 0). Some Reader implementations are very expensive to create (e.g. Xerces). Pooling Reader instances (i.e. reusing) can result in a huge performance improvement, especially when processing lots of "small" messages. The default value for this setting is 0 (i.e. unpooled - a new Reader instance is created for each message). Configure in line with your applications threading model. |
Troubleshooting
Smooks streams events that can be captured, and inspected, while in-flight or after execution. HtmlReportGenerator is one such class that inspects in-flight events to go on and generate an HTML report from the execution:
Smooks smooks = new Smooks("/smooks/smooks-transform-x.xml");
ExecutionContext executionContext = smooks.createExecutionContext();
executionContext.getContentDeliveryRuntime().addExecutionEventListener(new HtmlReportGenerator("/tmp/smooks-report.html"));
smooks.filterSource(executionContext, new StreamSource(inputStream), new StreamSink(outputStream));HtmlReportGenerator is a useful tool in the developer’s arsenal for diagnosing issues, or for comprehending a transformation.
An example HtmlReportGenerator report can be seen online here.
Of course you can also write and use your own ExecutionEventListener implementations.
| Only use the HTMLReportGenerator in development. When enabled, the HTMLReportGenerator incurs a significant performance overhead and with large message, can even result in OutOfMemory exceptions. |
Terminate
You can terminate Smooks’s filtering before it reaches the end of a stream. The following config terminates filtering at the end of the customer fragment:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd">
<!-- Visitors... -->
<core:terminate onElement="customer"/>
</smooks-resource-list>The default behavior is to terminate at the end of the targeted fragment, on the visitAfter event. To terminate at the start of the targeted fragment, on the visitBefore event, set the terminateBefore attribute to true:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd">
<!-- Visitors... -->
<core:terminate onElement="customer" terminateBefore="true"/>
</smooks-resource-list>Bean Context
The Bean Context is a container for objects which can be accessed within during a Smooks execution. One bean context is created per execution context, that is, per Smooks#filterSource(...) operation. Provide an org.smooks.io.sink.JavaSink object to Smooks#filterSource(...) if you want the contents of the bean context to be returned at the end of the filtering process:
//Get the data to filter
StreamSource source = new StreamSource(getClass().getResourceAsStream("data.xml"));
//Create a Smooks instance (cachable)
Smooks smooks = new Smooks("smooks-config.xml");
//Create the JavaSink, which will contain the filter result after filtering
JavaSink sink = new JavaSink();
//Filter the data from the source, putting the result into the JavaSink
smooks.filterSource(source, sink);
//Getting the Order bean which was created by the JavaBean cartridge
Order order = (Order)sink.getBean("order");Resources like visitors access the bean context’s beans at runtime from the BeanContext. The BeanContext is retrieved from ExecutionContext#getBeanContext(). You should first retrieve a BeanId from the BeanIdStore when adding or retrieving objects from the BeanContext. A BeanId is a special key that ensures higher performance then String keys, however String keys are also supported. The BeanIdStore must be retrieved from ApplicationContext#getBeanIdStore(). A BeanId object can be created by calling BeanIdStore#register(String). If you know that the BeanId is already registered, then you can retrieve it by calling BeanIdStore#getBeanId(String). BeanId is scoped at the application context. You normally register it in the @PostConstruct annotated method of your visitor implementation and then reference it as member variable from the visitBefore and visitAfter methods.
BeanId and BeanIdStore are thread-safe.
|
Pre-installed Beans
A number of pre-installed beans are available in the bean context at runtime:
The following are examples of how each of these would be used in a FreeMarker template.
Unique ID of the ExecutionContext:
${PUUID.execContext}
Random Unique ID:
${PUUID.random}
Filtering start time in milliseconds:
${PTIME.startMillis}
Filtering start time in nanoseconds:
${PTIME.startNanos}
Filtering start date:
${PTIME.startDate}
Current time in milliseconds:
${PTIME.nowMillis}
Current time in nanoSeconds:
${PTIME.nowNanos}
Current date:
${PTIME.nowDate}
Global Configurations
Global configuration settings are, as the name implies, configuration options that can be set once and be applied to all resources in a configuration.
Smooks supports two types of globals, default properties and global parameters:
-
Global Configuration Parameters: Every in a Smooks configuration can specify elements for configuration parameters. These parameter values are available at runtime through the
ResourceConfig, or are reflectively injected through the@Injectannotation. Global Configuration Parameters are parameters that are defined centrally (see below) and are accessible to all runtime components via theExecutionContext(vsResourceConfig). More on this in the following sections. -
Default Properties: Specify default values for attributes. These defaults are automatically applied to
ResourceConfigs when their corresponding does not specify the attribute. More on this in the following section.
Global Configuration Parameters
Global properties differ from the default properties in that they are not specified on the root element and are not automatically applied to resources.
Global parameters are specified in a <params> element:
<params>
<param name="xyz.param1">param1-val</param>
</params>Global Configuration Parameters are accessible via the ExecutionContext e.g.:
public void visitAfter(Element element, ExecutionContext executionContext) {
String param1 = executionContext.getConfigParameter("xyz.param1", "defaultValueABC");
....
}Default Properties
Default properties are properties that can be set on the root element of a Smooks configuration and have them applied to all resource configurations in smooks-conf.xml file. For example, if you have a resource configuration file in which all the resource configurations have the same selector value, you could specify a default-target-profile=order to save specifying the profile on every resource configuration:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
default-target-profile="order">
<resource-config>
<resource>com.acme.VisitorA</resource>
...
</resource-config>
<resource-config>
<resource>com.acme.VisitorB</resource>
...
</resource-config>
<smooks-resource-list>The following default configuration options are available:
-
default-target-profile*: Default target profile that will be applied to all resources in the smooks configuration file, where a target-profile is not defined. -
default-condition-ref: Refers to a global condition by the conditions id. This condition is applied to resources that define an empty "condition" element (i.e. ) that does not reference a globally defined condition.
Configuration Modularization
Smooks configurations are easily modularized through use of the <import> element. This allows you to split Smooks configurations into multiple reusable configuration files and then compose the top level configurations using the <import> element e.g.
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<import file="bindings/order-binding.xml" />
<import file="templates/order-template.xml" />
</smooks-resource-list>You can also inject replacement tokens into the imported configuration by using <param> sub-elements on the <import>. This allows you to make tweaks to the imported configuration.
<!-- Top level configuration... -->
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<import file="bindings/order-binding.xml">
<param name="orderRootElement">order</param>
</import>
</smooks-resource-list><!-- Imported parameterized bindings/order-binding.xml configuration... -->
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<jb:bean beanId="order" class="org.acme.Order" createOnElement="@orderRootElement@">
.....
</jb:bean>
</smooks-resource-list>Note how the replacement token injection points are specified using @tokenname@.
:imagesdir:
Consuming & Writing Data
CSV
This example shows an XML resource configuration of a CSV reader:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:csv="https://www.smooks.org/xsd/smooks/csv-1.7.xsd">
<!--
Configure the CSV to parse the message into a stream of SAX events.
-->
<csv:reader fields="firstname,lastname,gender,age,country" separator="|" quote="'" skipLines="1" />
</smooks-resource-list>The above configuration will generate an event stream of the form:
<csv-set>
<csv-record>
<firstname>Tom</firstname>
<lastname>Fennelly</lastname>
<gender>Male</gender>
<age>21</age>
<country>Ireland</country>
</csv-record>
<csv-record>
<firstname>Tom</firstname>
<lastname>Fennelly</lastname>
<gender>Male</gender>
<age>21</age>
<country>Ireland</country>
</csv-record>
</csv-set>Defining fields
Fields can be defined in either of two ways:
-
On the
fieldsattribute of the<csv:reader>configuration (as shown above). -
As the first record in the message after setting the
fieldsInMessageattribute of the<csv:reader>configuration totrue.
The field names must follow the same naming rules like XML element names:
-
Names can contain letters, numbers, and other characters
-
Names cannot start with a number or punctuation character
-
Names cannot start with the letters xml (or XML, or Xml, etc…)
-
Names cannot contain spaces
By setting the rootElementName and recordElementName attributes you can modify the and element names. The same naming rules apply for these names.
Multi-Record Field Definitions
All Flat File based reader configurations (including the CSV reader) support Multi-Record Field Definitions, which means that the reader can support CSV message streams containing varying (multiple different types) CSV record types.
Take the following CSV message example:
book,22 Britannia Road,Amanda Hodgkinson magazine,Time,April,2011 magazine,Irish Garden,Jan,2011 book,The Finkler Question,Howard Jacobson
In this stream, we have 2 record types of "book" and "magazine". We configure the CSV reader to process this stream as follows:
smooks-config.xml
<csv:reader fields="book[name,author] | magazine[*]" rootElementName="sales" indent="true" />This reader configuration will generate the following output for the above sample message:
<sales>
<book number="1">
<name>22 Britannia Road</name>
<author>Amanda Hodgkinson</author>
</book>
<magazine number="2">
<field_0>Time</field_0>
<field_1>April</field_1>
<field_2>2011</field_2>
</magazine>
<magazine number="3">
<field_0>Irish Garden</field_0>
<field_1>Jan</field_1>
<field_2>2011</field_2>
</magazine>
<book number="4">
<name>The Finkler Question</name>
<author>Howard Jacobson</author>
</book>
</sales>Note the syntax in the fields attribute. Each record definition is separated by the pipe character |. Each record definition is constructed as record-name[field-name,field-name]. record-name is matched against the first field in the incoming message and so used to select the appropriate record definition to be used for outputting that record. Also note how you can use an astrix character ('*') when you don’t want to name the record fields. In this case (as when extra/unexpected fields are present in a record), the reader will generate the output field elements using a generated element name e.g. "field_0", "field_1", etc… See the "magazine" record in the previous example.
Multi Record Field Definitions are not supported when the fields are defined in the message (fieldsInMessage="true").
|
String Manipulation Functions
Like the fixed-length cartridge, string manipulation functions can be defined per field. These functions are executed before that the data is converted into SAX events. The functions are defined after field name, separated with a question mark.
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:csv="https://www.smooks.org/xsd/smooks/csv-1.7.xsd">
<csv:reader fields="lastname?trim.capitalize,country?upper_case" />
</smooks-resource-list>Take a look at the fixed-length cartridge’s string manipulation functions to learn about the available functions and how the functions can be chained.
Ignoring Fields
One or more fields of a CSV record can be ignored by specifying the $ignore$ token in the fields configuration value. You can specify the number of fields to be ignored simply by following the $ignore$ token with a number e.g. $ignore$3 to ignore the next 3 fields. $ignore$+ ignores all fields to the end of the CSV record.
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:csv="https://www.smooks.org/xsd/smooks/csv-1.7.xsd">
<csv:reader fields="firstname,$ignore$2,age,$ignore$+" />
</smooks-resource-list>Binding CSV Records to Java
Smooks v1.2 added support for making the binding of CSV records to Java objects a very trivial task. You no longer need to use the Javabean Cartridge directly (i.e. Smooks main Java binding functionality).
This feature is not supported for Multi Record Field Definitions (see above), or when the fields are defined in the incoming message (fieldsInMessage="true").
|
A Persons CSV record set such as:
Tom,Fennelly,Male,4,Ireland Mike,Fennelly,Male,2,Ireland
Can be bound to a Person of (no getters/setters):
public class Person {
private String firstname;
private String lastname;
private String country;
private Gender gender;
private int age;
}
public enum Gender {
Male,
Female;
}Using a config of the form:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:csv="https://www.smooks.org/xsd/smooks/csv-1.7.xsd">
<csv:reader fields="firstname,lastname,gender,age,country">
<!-- Note how the field names match the property names on the Person class. -->
<csv:listBinding beanId="people" class="org.smooks.csv.Person" />
</csv:reader>
</smooks-resource-list>To execute this configuration:
Smooks smooks = new Smooks(configStream);
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(csvStream), sink);
List<Person> people = (List<Person>) sink.getBean("people");Smooks also supports creation of Maps from the CSV record set:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:csv="https://www.smooks.org/xsd/smooks/csv-1.7.xsd">
<csv:reader fields="firstname,lastname,gender,age,country">
<csv:mapBinding beanId="people" class="org.smooks.csv.Person" keyField="firstname" />
</csv:reader>
</smooks-resource-list>The above configuration would produce a map of Person instances, keyed by the "firstname" value of each Person. It would be executed as follows:
Smooks smooks = new Smooks(configStream);
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(csvStream), sink);
Map<String, Person> people = (Map<String, Person>) sink.getBean("people");
Person tom = people.get("Tom");
Person mike = people.get("Mike");Virtual Models are also supported, so you can define the class attribute as a java.util.Map and have the CSV field values bound into Map instances, which are in turn added to a List or a Map.
Java API
Programmatically configuring the CSV Reader on a Smooks instance is trivial. A number of options are available.
Configuring Directly on the Smooks Instance
The following code configures a Smooks instance with a CSVReader for reading a people record set (see above), binding the record set into a List of Person instances:
Smooks smooks = new Smooks();
smooks.setReaderConfig(new CSVReaderConfigurator("firstname,lastname,gender,age,country")
.setBinding(new CSVBinding("people", Person.class, CSVBindingType.LIST)));
JavaSink sink = new JavaSink();
smooks.filterSource(new ReaderSource(csvReader), sink);
List<Person> people = (List<Person>) sink.getBean("people");Of course configuring the Java binding is totally optional. The Smooks instance could instead (or in conjunction with) be programmatically configured with other visitors for carrying out other forms of processing on the CSV record set.
CSV List and Map Binders
If you’re just interested in binding CSV records directly onto a List or Map of a Java type that reflects the data in your CSV records, then you can use the CSVListBinder or CSVMapBinder classes.
CSVListBinder:
// Note: The binder instance should be cached and reused...
CSVListBinder binder = new CSVListBinder("firstname,lastname,gender,age,country", Person.class);
List<Person> people = binder.bind(csvStream);CSVMapBinder:
// Note: The binder instance should be cached and reused...
CSVMapBinder binder = new CSVMapBinder("firstname,lastname,gender,age,country", Person.class, "firstname");
Map<String, Person> people = binder.bind(csvStream);If you need more control over the binding process, revert back to the lower level APIs:
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-csv-cartridge</artifactId>
<version>2.0.3</version>
</dependency>XML Namespace
xmlns:csv="https://www.smooks.org/xsd/smooks/csv-1.7.xsd"
DFDL
The DFDL cartridge opens up Smooks to a wide array of data formats (e.g., SWIFT, ISO8583, HL7). In fact, this cartridge forms the foundation of the EDI and EDIFACT cartridges. The DFDL cartridge deserializes (i.e., parses) non-XML data and serializes (i.e., unparses) XML according to the structure described in a DFDL schema. DFDL (Data Format Description Language) is an open standard modeling language for describing general text and binary data. Take the subsequent DFDL schema as an example:
csv.dfdl.xsd
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:fn="http://www.w3.org/2005/xpath-functions"
xmlns:dfdl="http://www.ogf.org/dfdl/dfdl-1.0/" xmlns:ex="http://example.com"
targetNamespace="http://example.com" elementFormDefault="unqualified">
<xs:include schemaLocation="org/apache/daffodil/xsd/DFDLGeneralFormat.dfdl.xsd" />
<xs:annotation>
<xs:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:format ref="ex:GeneralFormat" separator="" initiator=""
terminator="" textTrimKind="none" initiatedContent="no" ignoreCase="no"
separatorPosition="infix" occursCountKind="implicit"
emptyValueDelimiterPolicy="both" representation="text" textNumberRep="standard"
lengthKind="delimited" encoding="ASCII" encodingErrorPolicy="error" />
</xs:appinfo>
</xs:annotation>
<xs:element name="file">
<xs:complexType>
<xs:sequence dfdl:separator="%NL;" dfdl:separatorPosition="postfix">
<xs:element name="header" minOccurs="0" maxOccurs="1"
dfdl:occursCountKind="implicit">
<xs:complexType>
<xs:sequence dfdl:separator=",">
<xs:element name="title" type="xs:string" maxOccurs="unbounded" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="record" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence dfdl:separator=",">
<xs:element name="item" type="xs:string" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>This schema describes the structure of CSV data like the one below:
input.csv
last,first,middle,DOB
smith,robert,brandon,1988-03-24
johnson,john,henry,1986-01-23
jones,arya,cat,1986-02-19A Smooks config parsing the above CSV using the DFDL cartridge would be written as:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:parser schemaUri="/csv.dfdl.xsd"/>
...
</smooks-resource-list>dfdl:parser is a reader and its schemaUri attribute references the DFDL schema driving the parsing behaviour. Assuming input.csv is the source, dfdl:parser will generate the event stream:
<ex:file xmlns:ex="http://example.com">
<header>
<title>last</title>
<title>first</title>
<title>middle</title>
<title>DOB</title>
</header>
<record>
<item>smith</item>
<item>robert</item>
<item>brandon</item>
<item>1988-03-24</item>
</record>
<record>
<item>johnson</item>
<item>john</item>
<item>henry</item>
<item>1986-01-23</item>
</record>
<record>
<item>jones</item>
<item>arya</item>
<item>cat</item>
<item>1986-02-19</item>
</record>
</ex:file>Shown in the next snippet is a pipeline enclosing the dfdl:unparser visitor:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
...
<core:smooks filterSourceOn="#document">
<core:action>
<core:inline>
<core:replace/>
</core:inline>
</core:action>
<core:config>
<smooks-resource-list>
<dfdl:unparser schemaUri="/csv.dfdl.xsd" unparseOnNode="*"/>
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>In contrast to the dfdl:parser schemaUri attribute, the schemaUri schema in dfdl:unparser drives the unparsing behaviour. dfdl:unparser replaces each node in the event stream with its serialized CSV counterpart, essentially implementing a pass-through application.
The DFDL cartridge supports variables, on disk caching, and trace debugging. Consult the XSD documentation for further information.
DFDL Guidance
Many DFDL schemas are freely available from the DFDL Schemas for Commercial and Scientific Data Formats GitHub repository. However, should you decide to author your own schemas, we strongly urge you first to gain a good understanding of DFDL. Resources to get started with DFDL include:
The next sections address common pitfalls to avoid when authoring DFDL schemas.
Validation
DFDL v1.0 supports data validation in the form of XSD constraints. Additional validation can be accomplished with the dfdl:assert statement as shown in the DFDL schema snippet below where the failureType attribute is equal to recoverableError so as not to interrupt parsing:
<xs:complexType name="FooType">
<xs:sequence>
<xs:element name="a" type="idl:int32">
<!-- Validate field a; recoverable error if fails -->
<xs:annotation>
<xs:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:assert test="{ . eq 1 }" failureType="recoverableError"/>
</xs:appinfo>
</xs:annotation>
</xs:element>
<xs:element name="b" type="idl:int32"/>
<xs:element name="c" type="idl:int32"/>
</xs:sequence>
</xs:complexType>Apart from XSD constraints and dfdl:assert statements, which are part of the DFDL specification, the DFDL implementation of this cartridge can fire Schematron rules. Despite these validation capabilities, we generally recommend that rich validation of the source is accomplished further downstream, either in Smooks itself or in a different application (e.g., Drools) altogether for the following reasons:
-
The stricter a DFDL schema is, the less portable it becomes across applications that have different definitions of data validity.
-
The validation rules need to be re-implemented if the
dfdl:parseris swapped out with a non-DFDL Smooks reader. -
Pluggable validators such as the Schematron validator load the whole DFDL infoset into memory which means that the Smooks application will not benefit from streaming.
-
Accidental complexity can creep in when business rules are applied to the DFDL infoset. Since a DFDL infoset emphasises the physical format of the data, these rules may become harder to understand compared to when they are applied to a simpler, logical structure. This is of particular relevance when the rules need to be written or tweaked by non-technical users, say, business analysts.
Mapping
The transformation features of DFDL should not be conflated with mapping. We highly recommend reading section 1.3 (What DFDL is not) of the DFDL specification which expands on this point. The XML schema structure must correspond more or less to the physical data format it is describing. While it is certainly possible to hide non-meaningful data in DFDL using hidden group elements and so on, if the data needs to be viewed in a very distinct way, then the general recommendation is to perform the mapping after parsing or before unparsing. For example, one should consider:
-
Parsing the source first with DFDL,
-
Mapping the streaming infoset (e.g., with XSLT, JavaBean cartridge, FreeMarker, etc…), to then
-
Feed the mapped result to the target consumer.
A possible solution for mapping the DFDL infoset is to leverage the core:rewrite reader in combination with a FreeMarker visitor, within a pipeline, as demonstrated in the pipelines example.
Parser reader options
Indent
Indent the generated event stream to make it easier to read. Useful for troubleshooting. The default value is false. Usage example:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:parser schemaUri="/csv.dfdl.xsd" indent="true"/>
</smooks-resource-list>Cache on disk
Persist DFDL schema on disk to reduce compilation time in subsequent runs. The default value is false. Usage example:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:parser schemaUri="/csv.dfdl.xsd" cacheOnDisk="true"/>
</smooks-resource-list>Validation mode
Validation modes for validating the resulting infoset against the DFDL schema. The following values are supported:
| Value | Description |
|---|---|
Off |
Turn off all validation against the DFDL schema. |
Limited |
Perform XSD validation of facets, minLength, maxLength, enumeration, minInclusive, minExclusive, maxInclusive, maxExclusive, and maxOccurs constraints. Validation failures will be printed in the log but will not interrupt parsing or unparsing. Validation failures can be retrieved from the Smooks execution context during or after execution using the |
Full |
Perform full schema validation using Xerces. A validation failure will abort parsing and throw a |
The default value for the validation mode is Off. Usage example:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:parser schemaUri="/csv.dfdl.xsd" validationMode="Limited"/>
</smooks-resource-list>Validation failures can be retrieved from the Smooks execution context as shown below:
...
org.smooks.Smooks smooks = new org.smooks.Smooks();
org.smooks.api.ExecutionContext executionContext = smooks.createExecutionContext();
smooks.filterSource(executionContext, source, sink);
List<org.apache.daffodil.japi.Diagnostic> diagnostics = executionContext.get(org.smooks.cartridges.dfdl.parser.DfdlParser.DIAGNOSTICS_TYPED_KEY);
...Debugging
Enable/disable trace debugging. The default value is false. Usage example:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:parser schemaUri="/csv.dfdl.xsd" debugging="true"/>
</smooks-resource-list>Schematron validation
Apply standalone or embedded Schematron rules within the DFDL schema. Note that Schematron validation leads to the input stream being loaded into memory therefore such validation is not recommended for large streams of data.
Standalone Schematron rules are applied like this:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:parser schemaUri="/csv.dfdl.xsd">
<dfdl:schematron url="rules.sch"/>
</dfdl:parser>
</smooks-resource-list>Embedded rules are applied as follows:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:parser schemaUri="/csv.dfdl.xsd">
<dfdl:schematron/>
</dfdl:parser>
</smooks-resource-list>Unparser visitor options
Cache on disk
Behaves identically to the dfdl:parser cache on disk attribute. Usage example:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:unparser schemaUri="/csv.dfdl.xsd" unparseOnNode="*" cacheOnDisk="true"/>
</smooks-resource-list>Validation mode
Behaves identically to the dfdl:parser validation attribute. Usage example:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:unparser schemaUri="/csv.dfdl.xsd" unparseOnNode="*" validationMode="Limited"/>
</smooks-resource-list>Debugging
Behaves identically to the dfdl:parser debugging attribute. Usage example:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd">
<dfdl:unparser schemaUri="/csv.dfdl.xsd" unparseOnNode="*" debugging="true"/>
</smooks-resource-list>Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-dfdl-cartridge</artifactId>
<version>1.0.3</version>
</dependency>XML Namespace
xmlns:dfdl="https://www.smooks.org/xsd/smooks/dfdl-1.0.xsd"
EDI
The EDI cartridge inherits from the DFDL cartridge to provide a schema-driven reader for parsing EDI documents, and a schema-driven visitor for serialising the event stream into EDI. Many of the options that are available from the DFDL cartridge are supported in the EDI cartridge as well (e.g., validation mode). Moreover, the guidance on DFDL is also highly relevant to the EDI schemas.
In the following pass-through configuration, Smooks parses an EDI document and then serialises, or unparses in DFDL nomenclature, the generated event stream to produce an EDI document identical to the parsed document.
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:edi="https://www.smooks.org/xsd/smooks/edi-2.0.xsd">
<!-- Configure the reader to parse the EDI stream into a stream of SAX events. -->
<edi:parser schemaUri="/edi-to-xml-mapping.dfdl.xsd" (1)
segmentTerminator="%NL;" (2)
compositeDataElementSeparator="^"/> (3)
<!-- Apply a pipeline on the root event and replace the XML result produced from <edifact:parser .../> with the pipeline EDI result. -->
<core:smooks filterSourceOn="/Order">
<core:action>
<core:inline>
<core:replace/>
</core:inline>
</core:action>
<core:config>
<smooks-resource-list>
<!-- Configure the writer to serialise the event stream into EDI. -->
<edi:unparser schemaUri="/edi-to-xml-mapping.dfdl.xsd" (1)
segmentTerminator="%NL;" (2)
compositeDataElementSeparator="^" (3)
unparseOnNode="*"/> (4)
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>Config attributes common to the parser and unparser resources are:
-
schemaUri: the DFDL schema describing the structure of the EDI document to be parser or unparsed.the schemaUriattribute is optional starting from EDI Cartridge v2.1.0. LeavingschemaUriunset means that the resource will default to the bundled schemaedi.dfdl.xsd. This general-purpose DFDL schema defines an unopinionated EDI structure which can be used for parsing or unparsing most flavours of EDI. -
segmentTerminator: the terminator for groups of related data elements. DFDL interprets%NL;as a newline. -
compositeDataElementSeparator: the delimiter for compound data elements.
The unparseOnNode attribute is exclusive to the unparser visitor. It tells the unparser which event to intercept and serialise. Consult with the EDI cartridge’s XSD documentation for the complete list of config attributes and elements.
EDI DFDL Schema
The user-defined DFDL schema supplied to the parser and unparser config elements drives the event mapping, whether it is EDI to SAX or SAX to EDI. This schema must import the bundled IBM_EDI_Format.dfdl.xsd DFDL schema which defines common EDI constructs like segments and data elements.
The following figure illustrates the mapping process:

-
input-message.edi is the input/output EDI document.
-
edi-to-xml-order-mapping.dfdl.xsd describes the EDI to SAX, or SAX to EDI, event mapping.
-
expected.xml is the result event stream from applying the mapping.
Segments
The next snippet shows a segment declaration in DFDL:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dfdl="http://www.ogf.org/dfdl/dfdl-1.0/"
xmlns:ibmEdiFmt="http://www.ibm.com/dfdl/EDI/Format">
<xsd:import namespace="http://www.ibm.com/dfdl/EDI/Format" schemaLocation="/EDIFACT-Common/IBM_EDI_Format.dfdl.xsd"/>
<xsd:annotation>
<xsd:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:format ref="ibmEdiFmt:EDIFormat"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element dfdl:initiator="HDR" (1)
name="header" (2)
dfdl:ref="ibmEdiFmt:EDISegmentFormat"> (3)
<xsd:complexType>
...
</xsd:complexType>
</xsd:element>
</xsd:schema>| 1 | dfdl:initiator identifies the segment code . |
| 2 | name attribute specifies the segment’s XML mapping. |
| 3 | ibmEdiFmt:EDISegmentFormat holds the segment structure definition; it is important to reference it from within the dfdl:ref attribute. |
Segment Cardinality
What is not demonstrated in the previous section is the segment element’s optional attributes minOccurs and maxOccurs (default value of 1 in both cases). These attributes can be used to control the optional and required characteristics of a segment. An unbounded maxOccurs indicates that the segment can repeat any number of times in that location of the EDI document.
Segment Groups
You implicitly create segment groups when:
-
Setting the
maxOccursin a segment element to more than one, and -
Adding within the segment element other segment elements
The HDR segment in the next example is a segment group because it is unbounded, and it encloses the CUS and ORD segments:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dfdl="http://www.ogf.org/dfdl/dfdl-1.0/"
xmlns:ibmEdiFmt="http://www.ibm.com/dfdl/EDI/Format">
<xsd:import namespace="http://www.ibm.com/dfdl/EDI/Format" schemaLocation="/EDIFACT-Common/IBM_EDI_Format.dfdl.xsd"/>
<xsd:annotation>
<xsd:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:format ref="ibmEdiFmt:EDIFormat"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element dfdl:initiator="HDR" name="order" maxOccurs="unbounded">
<xsd:complexType>
<xsd:sequence>
<xsd:sequence dfdl:ref="ibmEdiFmt:EDISegmentFormat">
...
</xsd:sequence>
<xsd:element dfdl:initiator="CUS" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="customer-details">
<xsd:complexType>
...
</xsd:complexType>
</xsd:element>
<xsd:element dfdl:initiator="ORD" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="order-item"
maxOccurs="unbounded">
<xsd:complexType>
...
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>Data Elements
Segment data elements are children within a sequence element referencing the DFDL format ibmEdiFmt:EDISegmentSequenceFormat:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dfdl="http://www.ogf.org/dfdl/dfdl-1.0/"
xmlns:ibmEdiFmt="http://www.ibm.com/dfdl/EDI/Format">
<xsd:import namespace="http://www.ibm.com/dfdl/EDI/Format" schemaLocation="/EDIFACT-Common/IBM_EDI_Format.dfdl.xsd"/>
<xsd:annotation>
<xsd:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:format ref="ibmEdiFmt:EDIFormat"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element dfdl:initiator="HDR" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="header">
<xsd:complexType>
<xsd:sequence dfdl:ref="ibmEdiFmt:EDISegmentSequenceFormat">
<xsd:element name="order-id" type="xsd:string"/>
<xsd:element name="status-code" type="xsd:string"/>
<xsd:element name="net-amount" type="xsd:string"/>
<xsd:element name="total-amount" type="xsd:string"/>
<xsd:element name="tax" type="xsd:string"/>
<xsd:element name="date" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>Each child xsd:element within xsd:sequence represents an EDI data element. The name attribute is the name of the target XML element capturing the data element’s value.
Composite Data Elements
Data elements made up of components are yet another xsd:sequence referencing the DFDL format ibmEdiFmt:EDICompositeSequenceFormat:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dfdl="http://www.ogf.org/dfdl/dfdl-1.0/"
xmlns:ibmEdiFmt="http://www.ibm.com/dfdl/EDI/Format">
<xsd:import namespace="http://www.ibm.com/dfdl/EDI/Format" schemaLocation="/EDIFACT-Common/IBM_EDI_Format.dfdl.xsd"/>
<xsd:annotation>
<xsd:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:format ref="ibmEdiFmt:EDIFormat"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element dfdl:initiator="CUS" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="customer-details">
<xsd:complexType>
<xsd:sequence dfdl:ref="ibmEdiFmt:EDISegmentSequenceFormat">
<xsd:element name="username" type="xsd:string"/>
<xsd:element name="name">
<xsd:complexType>
<xsd:sequence dfdl:ref="ibmEdiFmt:EDICompositeSequenceFormat">
<xsd:element name="firstname" type="xsd:string"/>
<xsd:element name="lastname" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="state" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>Imports
Many EDI messages use the same segment definitions. Being able to define these segments once and import them into a top-level configuration saves on duplication. A simple configuration demonstrating the import feature would be as follows:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dfdl="http://www.ogf.org/dfdl/dfdl-1.0/"
xmlns:ibmEdiFmt="http://www.ibm.com/dfdl/EDI/Format"
xmlns:def="def">
<xsd:import namespace="http://www.ibm.com/dfdl/EDI/Format" schemaLocation="/EDIFACT-Common/IBM_EDI_Format.dfdl.xsd"/>
<xsd:import namespace="def" schemaLocation="example/edi-segment-definition.xml"/>
<xsd:annotation>
<xsd:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:format ref="ibmEdiFmt:EDIFormat"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Order">
<xsd:complexType>
<xsd:sequence>
<xsd:sequence dfdl:initiatedContent="yes">
<xsd:element dfdl:initiator="HDR" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="header" type="def:HDR"/>
<xsd:element dfdl:initiator="CUS" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="customer-details" type="def:CUS"/>
<xsd:element dfdl:initiator="ORD" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="order-item" maxOccurs="unbounded" type="def:ORD"/>
</xsd:sequence>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>The above schema demonstrates the use of the import element, where just about anything can be moved into its own file for reuse.
Type Support
The type attribute on segment data elements allows datatype specification for validation. The following example shows type support in action:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dfdl="http://www.ogf.org/dfdl/dfdl-1.0/"
xmlns:ibmEdiFmt="http://www.ibm.com/dfdl/EDI/Format">
<xsd:import namespace="http://www.ibm.com/dfdl/EDI/Format" schemaLocation="/EDIFACT-Common/IBM_EDI_Format.dfdl.xsd"/>
<xsd:annotation>
<xsd:appinfo source="http://www.ogf.org/dfdl/">
<dfdl:format ref="ibmEdiFmt:EDIFormat"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element dfdl:initiator="HDR" dfdl:ref="ibmEdiFmt:EDISegmentFormat" name="header">
<xsd:complexType>
<xsd:sequence dfdl:ref="ibmEdiFmt:EDISegmentSequenceFormat">
<xsd:element name="order-id" type="xsd:string"/>
<xsd:element name="status-code" type="xsd:int" dfdl:textNumberPattern="0"/>
<xsd:element name="net-amount" type="xsd:decimal" dfdl:textNumberPattern="0"/>
<xsd:element name="total-amount" type="xsd:decimal" dfdl:textNumberPattern="#.#"/>
<xsd:element name="tax" type="xsd:decimal" dfdl:textNumberPattern="#.#"/>
<xsd:element name="date" type="xsd:date"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges.edi</groupId>
<artifactId>smooks-edi-cartridge</artifactId>
<version>2.1.0</version>
</dependency>XML Namespaces
xmlns:edi="https://www.smooks.org/xsd/smooks/edi-2.0.xsd"
EDIFACT
Smooks 2 provides out-of-the-box support for UN EDIFACT interchanges in terms of pre-generated EDI DFDL schemas derived from the official UN EDIFACT
message definition zip directories. This allows you to easily convert a UN EDIFACT message interchange into a consumable XML document. Specialised edifact:parser and edifact:unparser resources support UN EDIFACT interchanges as shown in the next example:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:edifact="https://www.smooks.org/xsd/smooks/edifact-2.0.xsd">
<!-- Configure the reader to parse the EDIFACT stream into a stream of SAX events. -->
<edifact:parser schemaUri="/d03b/EDIFACT-Messages.dfdl.xsd"/>
<!-- Apply a pipeline on the root event and replace the XML result produced from <edifact:parser .../> with the pipeline EDIFACT result. -->
<core:smooks filterSourceOn="/Interchange">
<core:action>
<core:inline>
<core:replace/>
</core:inline>
</core:action>
<core:config>
<smooks-resource-list>
<!-- Configure the writer to serialise the event stream into EDIFACT. -->
<edifact:unparser schemaUri="/d03b/EDIFACT-Messages.dfdl.xsd" unparseOnNode="*"/>
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>The edifact:parser and edifact:unparser, analogous to the edi:parser and edi:unparser, convert the stream according to the pre-generated DFDL schema referenced in the schemaUri attribute. Given that an EDIFACT schema can be very big compared to your average EDI schema, it may take minutes for the parser to compile it. Even having the cacheOnDisk attribute enabled may not be sufficient to meet your compilation time needs. For such situations, you can mitigate this problem by declaring ahead of time which message types the parser will process:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:edifact="https://www.smooks.org/xsd/smooks/edifact-2.0.xsd">
<edifact:parser schemaUri="/d03b/EDIFACT-Messages.dfdl.xsd">
<edifact:messageTypes>
<edifact:messageType>ORDERS</edifact:messageType>
<edifact:messageType>INVOIC</edifact:messageType>
</edifact:messageTypes>
</edifact:parser>
<core:smooks filterSourceOn="/Interchange">
<core:action>
<core:inline>
<core:replace/>
</core:inline>
</core:action>
<core:config>
<smooks-resource-list>
<edifact:unparser schemaUri="/d03b/EDIFACT-Messages.dfdl.xsd" unparseOnNode="*">
<edifact:messageTypes>
<edifact:messageType>ORDERS</edifact:messageType>
<edifact:messageType>INVOIC</edifact:messageType>
</edifact:messageTypes>
</edifact:unparser>
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>The schema compilation time is directly proportional to the number of declared message types. The EDIFACT resources will reject any message which does not have its message type declared within the messageTypes child element. Apart from XML configuration, it is also possible to programmatically control the EDIFACT parser message types via a EdifactReaderConfigurator instance:
Smooks smooks = new Smooks();
smooks.setReaderConfig(new EdifactReaderConfigurator("/d03b/EDIFACT-Messages.dfdl.xsd").setMessageTypes(Arrays.asList("ORDERS", "INVOIC")));
etc...Schema Packs
In an effort to simplify the processing of UN EDIFACT Interchanges, we have created tools to generate EDIFACT schema packs from the official UN EDIFACT message definition zip directories. The generated schema packs are deployed to a public Maven repository from where users can easily access the EDIFACT schemas for the UN EDIFACT message sets they need to support.
Schema packs are available for most of the UN EDIFACT directories. These are available from the Maven Snapshot and Central repositories and can be added to your application using standard Maven dependency management.
As an example, to add the D93A DFDL schema pack to your application classpath, add the following dependency to your application’s POM:
pom.xml
<!-- The mapping model sip set for the D93A directory... -->
<dependency>
<groupId>org.smooks.cartridges.edi</groupId>
<artifactId>edifact-schemas</artifactId>
<classifier>d93a</classifier>
<version>2.1.0</version>
</dependency>Once you add an EDIFACT schema pack set to the application’s classpath, you configure Smooks to use the schemas by referencing the root schema in schemaUri attribute of the edifact:parser or edifact:unparser configuration (<version>/EDIFACT-Messages.dfdl.xsd):
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:edifact="https://www.smooks.org/xsd/smooks/edifact-1.0.xsd">
<edifact:parser schemaUri="/d03b/EDIFACT-Messages.dfdl.xsd">
<edifact:messages>
<edifact:message>ORDERS</edifact:message>
<edifact:message>INVOIC</edifact:message>
</edifact:messages>
</edifact:parser>
</smooks-resource-list>See the EDIFACT examples for further reference.
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges.edi</groupId>
<artifactId>smooks-edifact-cartridge</artifactId>
<version>2.1.0</version>
</dependency>XML Namespaces
xmlns:edifact="https://www.smooks.org/xsd/smooks/edifact-2.0.xsd"
Fixed-Length
A simple/basic fixed-length reader configuration:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:fl="https://www.smooks.org/xsd/smooks/fixed-length-1.4.xsd">
<!-- Configure the fixed-length reader to parse the message into a stream of SAX events. -->
<fl:reader fields="firstname[10],lastname[10],gender[1],age[2],country[2]" skipLines="1" />
</smooks-resource-list>Example input file:
#HEADER Tom Fennelly M 21 IE Maurice Zeijen M 27 NL
The above configuration will generate an event stream of the form:
<set>
<record>
<firstname>Tom </firstname>
<lastname>Fennelly </lastname>
<gender>M</gender>
<age> 21</age>
<country>IE</country>
</record>
<record>
<firstname>Maurice </firstname>
<lastname>Zeijen </lastname>
<gender>M</gender>
<age>27</age>
<country>NL</country>
</record>
</set>Defining fields
Fields are defined in the 'fields' attribute as a comma separated list of names and field lengths. The field lengths must be defined between the brackets after the field name (see the example above).
The field names must follow the same naming rules like XML element names:
-
Names can contain letters, numbers, and other characters
-
Names cannot start with a number or punctuation character
-
Names cannot start with the letters xml (or XML, or Xml, etc…)
-
Names cannot contain spaces
By setting the rootElementName and recordElementName attributes you can modify the and element names. The same naming rules apply for these names.
String manipulation functions
String manipulation functions can be defined per field. These functions are executed before that the data is converted into SAX events. The functions are defined after the field length definitions and are optionally separated with a question mark.
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:fl="https://www.smooks.org/xsd/smooks/fixed-length-1.4.xsd">
<!-- Configure the fixed-length reader to parse the message into a stream of SAX events. -->
<fl:reader fields="firstname[10]?trim,lastname[10]trim.capitalize,gender[1],age[2],country[2]" skipLines="1" />
</smooks-resource-list>The following functions are available:
-
upper_case: Returns the upper case version of the string. -
lower_case: Returns the lower case version of the string. -
cap_first: Returns the string with the very first word of the string capitalized. -
uncap_first: Returns the string with the very first word of the string un-capitalized. The opposite tocap_first. -
capitalize: Returns the string with all words capitalized. -
trim: Returns the string without leading and trailing white-spaces. -
left_trim: Returns the string without leading white-spaces. -
right_trim: Returns the string without trailing white-spaces.
Functions can be chained via the point separator: trim.upper_case. It depends on the reader how the functions are defined per field. Please look at the individual chapters of the readers for that information.
Ignoring Fields
Characters ranges of a fixed-length record can be ignored by specifying the $ignore$[10] token in the fields configuration value. You must specify the number of characters that need be ignored, just as a normal field.
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:fl="https://www.smooks.org/xsd/smooks/fixed-length-1.4.xsd">
<fl:reader fields="firstname,$ignore$[2],age,$ignore$[10]" />
</smooks-resource-list>Binding Fixed-Length Records to Java
Smooks v1.2 has added support for making the binding of fixed-length records to Java Objects a very trivial task. You don’t need to use the Javabean Cartridge directly (i.e. Smooks main Java binding functionality).
A Persons fixed-length record set such as:
Tom Fennelly M 21 IE Maurice Zeijen M 27 NL
Can be bound to a Person of (no getters/setters):
Person.java
public class Person {
private String firstname;
private String lastname;
private String country;
private String gender;
private int age;
}Using a config of the form:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:fl="https://www.smooks.org/xsd/smooks/fixed-length-1.4.xsd">
<fl:reader fields="firstname[10]?trim,lastname[10]?trim,gende[1],age[3]?trim,country[2]">
<!-- Note how the field names match the property names on the Person class. -->
<fl:listBinding beanId="people" class="org.smooks.fixedlength.Person" />
</fl:reader>
</smooks-resource-list>To execute this configuration:
Smooks smooks = new Smooks(configStream);
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(fixedLengthStream), sink);
List<Person> people = (List<Person>) sink.getBean("people");Smooks also supports creation of maps from the fixed-length record set:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:csv="https://www.smooks.org/xsd/smooks/csv-1.7.xsd">
<csv:reader fields="firstname,lastname,gender,age,country">
<csv:mapBinding beanId="people" class="org.smooks.csv.Person" keyField="firstname" />
</csv:reader>
</smooks-resource-list>The above configuration would produce a map of Person instances, keyed by the "firstname" value of each Person. It would be executed as follows:
Smooks smooks = new Smooks(configStream);
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(fixedLengthStream), sink);
Map<String, Person> people = (Map<String, Person>) sink.getBean("people");
Person tom = people.get("Tom");
Person mike = people.get("Maurice");Virtual Models are also supported, so you can define the class attribute as a java.util.Map and have the fixed-length field values bound into Map instances, which are in turn added to a list or a map.
Java API
Programmatically configuring the FixedLengthReader on a Smooks instance is trivial. A number of options are available.
Configuring Directly on the Smooks Instance
The following code configures a Smooks instance with a FixedLengthReader for reading a people record set (see above), binding the record set into a List of Person instances:
Smooks smooks = new Smooks();
smooks.setReaderConfig(new FixedLengthReaderConfigurator("firstname,lastname,gender,age,country")
.setBinding(new FixedLengthBinding("people", Person.class, CSVBindingType.LIST)));
JavaSink sink = new JavaSink();
smooks.filterSource(new ReaderSource(csvReader), sink);
List<Person> people = (List<Person>) sink.getBean("people");Of course configuring the Java Binding is totally optional. The Smooks instance could instead (or in conjunction with) be programmatically configured with other visitor for carrying out other forms of processing on the fixed-length record set.
Fixed-Length List & Map Binders
If you’re just interested in binding fixed-length records directly onto a List or Map of a Java type that reflects the data in your fixed-length records, then you can use the FixedLengthListBinder or FixedLengthMapBinder classes.
FixedLengthListBinder:
// Note: The binder instance should be cached and reused...
FixedLengthListBinder binder = new FixedLengthListBinder("firstname[10]?trim,lastname[10]?trim,gender[1],age[3]?trim,country[2]", Person.class);
List<Person> people = binder.bind(fixedLengthStream);FixedLengthMapBinder:
// Note: The binder instance should be cached and reused...
FixedLengthMapBinder binder = new FixedLengthMapBinder("firstname[10]?trim,lastname[10]?trim,gender[1],age[3]?trim,country[2]", Person.class, "firstname");
Map<String, Person> people = binder.bind(fixedLengthStream);If you need more control over the binding process, revert back to the lower level APIs:
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-fixed-length-cartridge</artifactId>
<version>2.0.3</version>
</dependency>XML Namespace
xmlns:fl="https://www.smooks.org/xsd/smooks/fixed-length-1.4.xsd"
JavaBeans
Smooks can map a Java object graph to another Java object graph. This mapping is accomplished through events, which means no intermediate object is constructed for populating the target Java object graph. In other words, the source Java object graph is turned into a stream of events that are bound to the target Java object graph.
Consider an Order object needing to be mapped to a LineOrder object. Conceptually, the mapping from the source to target object model would be:
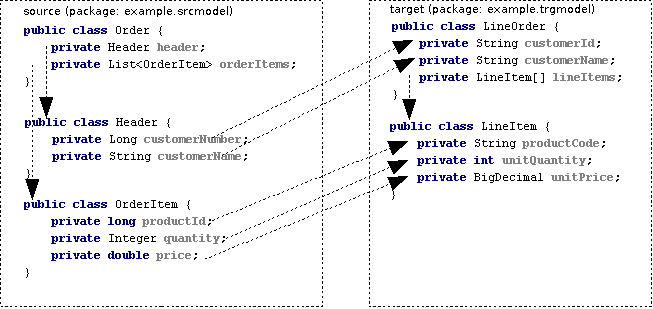
One can easily view the event stream produced from the source object (i.e., Order) if Smooks’s HTML Report Generator is running:
<example.srcmodel.Order>
<header>
<customerNumber>...</customerNumber>
<customerName>...</customerName>
</header>
<orderItems>
<example.srcmodel.OrderItem>
<productId>...</productId>
<quantity>...</quantity>
<price>...</price>
</example.srcmodel.OrderItem>
</orderItems>
</example.srcmodel.Order>Mapping the source object is a matter of targeting the Smooks Javabean resources at the above event stream. Such a Smooks config performing the mapping would look like:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<jb:bean beanId="lineOrder" class="example.trgmodel.LineOrder" createOnElement="example.srcmodel.Order">
<jb:wiring property="lineItems" beanIdRef="lineItems" />
<jb:value property="customerId" data="header/customerNumber" />
<jb:value property="customerName" data="header/customerName" />
</jb:bean>
<jb:bean beanId="lineItems" class="example.trgmodel.LineItem[]" createOnElement="orderItems">
<jb:wiring beanIdRef="lineItem" />
</jb:bean>
<jb:bean beanId="lineItem" class="example.trgmodel.LineItem" createOnElement="example.srcmodel.OrderItem">
<jb:value property="productCode" data="example.srcmodel.OrderItem/productId" />
<jb:value property="unitQuantity" data="example.srcmodel.OrderItem/quantity" />
<jb:value property="unitPrice" data="example.srcmodel.OrderItem/price" />
</jb:bean>
</smooks-resource-list>Java to Java
The source object is provided to Smooks via a org.smooks.io.source.JavaSource instance. This object is created by passing the constructor the root object of the source model. The resulting JavaSource object is used in the Smooks#filter method. The resulting code could look like as follows:
protected LineOrder runSmooksTransform(Order srcOrder) throws Exception {
Smooks smooks = new Smooks("smooks-config.xml");
ExecutionContext executionContext = smooks.createExecutionContext();
// Transform the source Order to the target LineOrder via a
// JavaSource and JavaSink instance...
JavaSource source = new JavaSource(srcOrder);
JavaSink sink = new JavaSink();
// Configure the execution context to generate a report...
executionContext.setEventListener(new HtmlReportGenerator("target/report/report.html"));
smooks.filterSource(executionContext, source, sink);
return (LineOrder) sink.getBean("lineOrder");
}Java to Text (XML, CSV, EDI, etc…)
The Smooks core runtime works by processing a stream of SAX events produced by an input source of some type (XML, EDI, Java, etc…) and using those events to fire visitors. In the case of a Java source (see previous section on "Java to Java"), Smooks uses XStream to generate this stream of SAX events.
Sometimes, however, you just want to apply a template (e.g. a FreeMarker template) to a Java Source object model and produce XML, CSV, EDI, etc… You don’t want to incur the wasted overhead of generating a stream of SAX events that you are not going to use. To do this, you need to tell the Smooks core runtime to not generate the stream of events. This can be done in one of two ways.
By calling setEventStreamRequired(false) on the JavaSource instance being supplied to Smooks.filterSource:
JavaSource javaSource = new JavaSource(orderBean);
// Turn streaming off via the JavaSource...
javaSource.setEventStreamRequired(false);
smooks.filterSource(javaSource, sink);Or, by turning off the "http://www.smooks.org/sax/features/generate-java-event-stream" <reader> feature in the Smooks configuration:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<reader>
<features>
<setOff feature="http://www.smooks.org/sax/features/generate-java-event-stream" />
</features>
</reader>
<!-- Other Smooks configurations e.g. a FreeMarker template... -->
</smooks-resource-list>When applying the FreeMarker template, the name of the templating context beans (i.e. the names used in your template) depends on the Object type in the JavaSource:
-
If the object is a
Map, then that Map instance becomes the templating context and so you can just use the Map entry keys as the bean names in your template. -
For non-map objects, the
JavaSourceclass takes the Object Class SimpleName and creates a JavaBean property name from it. This is the name of the context bean used for the templating. So, if the bean class name iscom.acme.Order, then the context bean name, for the purpose of templating, will be "order".
Java Binding
The JavaBean Cartridge allows you to create and populate Java POJOs from your message data (i.e., bind data).
Java Binding Overview
This feature of Smooks can be used in its own right purely as a Java binding framework for XML, EDI, CSV, etc… However, it is very important to remember that the Java Binding capabilities in Smooks are the cornerstone of many other capabilities provided by Smooks. This is because Smooks makes the Java objects it creates (and binds data into) available through the BeanContext class. This is essentially a Java Bean context that is made available to any Smooks visitor via the Smooks ExecutionContext.
Some of the existing features that build on the functionality provided in the JavaBean Cartridge include:
-
Templating: Templating typically involves applying a template (FreeMarker or other) to the objects in the BeanContext.
-
Validation: Business Rules Validation (e.g. via MVEL) typically involves applying a rule (expression, etc…) to the objects in the BeanContext.
-
Message Splitting & Routing: Message Splitting typically works by generating split messages from the Objects in the BeanContext, either by using the objects themselves and routing them, or by applying a template to them and routing the result of that templating operation (e.g. a new XML, CSV, etc…).
-
Persistence (Database Reading and Writing): The Persistence features depend on the Java Binding functions for creating and populating the Java objects (Entities etc) to be persisted. Data read from a database is typically bound into the BeanContext.
-
Message Enrichment: As stated above, enrichment data (e.g. read from a DB) is typically bound into the BeanContext, from where it is available to all other features, including the Java Binding functionality itself e.g. for expression-based bindings. This allows messages generated by Smooks to be enriched.
When to use Smooks Java Binding
A question that often comes to mind is "Why would I use Smooks to perform binding to a Java objects model instead of JAXB or JiBX?". Well there are a number of reasons why you would use Smooks and there are a number of reasons why you would not use Smooks.
When Smooks makes sense:
-
Binding non-XML data to a Java object model e.g. EDI, CSV, JSON, etc…
-
Binding data (XML or other) whose data model (hierarchical structure) does not match that of the target Java object model. JiBX also supports this, but only for XML (AFAIK!!).
-
When you are binding data from an XML data structure for which there is no defined schema (XSD). Some frameworks effectively require a well defined XML data model via schema.
-
When binding data from multiple existing and different data formats into a single pre-existing Java object model. Related to the above points.
-
When binding data into existing 3rd Party Object Models that you cannot modify e.g. through a post-compile step.
-
In situations where the Data (XML or other) and Java object models may vary in isolation from each other. Because of #2 above, Smooks can handle this by simply modifying the binding configuration. Other frameworks often require binding/schema regeneration, redeployment, etc… (see #3 above).
-
Where you need to execute additional logic in parallel to the binding process e.g. Validation, Split Message Generation (via Templates), Split Message Routing, Fragment Persistence, or any custom logic that you may wish to implement. This is often a very powerful capability e.g. when processing huge message streams.
-
Processing huge message streams by splitting them into a series of many small object models and routing them to other systems for processing.
-
When using other Smooks features that rely on the Smooks Java Binding capabilities.
When Smooks may not make sense:
-
When you have a well defined data model (via schema/XSD) and all you need to do is bind data into an object model (no required validation, persistence, etc…).
-
When the object model is isolated from other systems and so can change without impacting such systems.
-
Where processing XML and performance is paramount over all other considerations (where nanoseconds matter), frameworks such as JiBX are definitely worth considering over Smooks. This is not to imply that the performance of Smooks Java Binding is poor in any way, but it does acknowledge the fact that frameworks that utilise post-compile optimizations targeted at a specific data format (e.g. XML) will always have the edge under the right conditions.
Basics of Java Binding
As you know, Smooks supports a range of source data formats (XML, EDI, CSV, Java, etc…), but for the purposes of this topic, we will always refer to the message data in terms of an XML format. In the examples, we will continuously refer to the following XML message:
<order>
<header>
<date>Wed Nov 15 13:45:28 EST 2006</date>
<customer number="123123">Joe</customer>
</header>
<order-items>
<order-item>
<product>111</product>
<quantity>2</quantity>
<price>8.90</price>
</order-item>
<order-item>
<product>222</product>
<quantity>7</quantity>
<price>5.20</price>
</order-item>
</order-items>
</order>In some examples we will use different XML message data. Where this happens, the data is explicitly defined there then.
The JavaBean Cartridge is used via the https://www.smooks.org/xsd/smooks/javabean-1.6.xsd configuration namespace. Install the schema in your IDE and avail of autocompletion.
An example configuration:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<jb:bean beanId="order" class="example.model.Order" createOnElement="#document" />
</smooks-resource-list>This configuration simply creates an instance of the example.model.Order class and binds it into the bean context under the beanId order. The instance is created at the very start of the message on the #document element (i.e. the start of the root element).
-
beanId: The id of this bean. Please see The Bean Context for more details. -
class: The fully qualified class name of the bean. -
createOnElement: attribute controls when the bean instance is created. Population of the bean properties is controlled through the binding configurations (child elements of the element).
The JavaBean cartridge has the following conditions for javabeans:
-
A public no-argument constructor
-
Public property setter methods. The don’t need to follow any specific name formats, but it would be better if they do follow the standard property setter method names.
-
Setting javabean properties directly is not supported.
Java Binding Configuration Details
The configuration shown above simply created the example.model.Order bean instance and bound it into the bean context. This section will describe how to bind data into that bean instance.
The JavaBean Cartridge provides support for 3 types of data bindings, which are added as child elements of the <jb:bean> element:
-
<jb:value>: This is used to bind data values from the Source message event stream into the target bean. -
<jb:wiring>: This is used to "wire" another bean instance from the bean context into a bean property on the target bean. This is the configuration that allows you to construct an object graph (Vs just a loose bag of Java object instances). Beans can be wired in based on their "beanId", their Java class type, or by Annotation (by being annotated with a specific Annotation). -
<jb:expression>: As it’s name suggests, this configuration is used to bind in a value calculated from an expression (in the MVEL language), a simple example being the binding of an order item total value into an OrderItem bean based on the result of an expression that calculates the value from the items price and quantity (e.g. "price * quantity"). TheexecOnElementattribute expression defines the element on which the expression is to be evaluated and the result bound. If not defined, the expression is executed based on the value of the parent . The value of the targeted element is available in the expression as a String variable under the name_VALUE(notice the underscore).
Taking the Order XML message (previous section), lets see what the full XML to Java binding configuration might be. We’ve seen the order XML (above). Now lets look at the Java objects that we want to populate from that XML message (getters and setters not shown):
public class Order {
private Header header;
private List<OrderItem> orderItems;
}
public class Header {
private Date date;
private Long customerNumber;
private String customerName;
private double total;
}
public class OrderItem {
private long productId;
private Integer quantity;
private double price;
}The Smooks config required to bind the data from the order XML and into this object model is as follows:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd" xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
(1) <jb:bean beanId="order" class="com.acme.Order" createOnElement="order">
(1.a) <jb:wiring property="header" beanIdRef="header" />
(1.b) <jb:wiring property="orderItems" beanIdRef="orderItems" />
</jb:bean>
(2) <jb:bean beanId="header" class="com.acme.Header" createOnElement="order">
(2.a) <jb:value property="date" decoder="Date" data="header/date">
<jb:decodeParam name="format">EEE MMM dd HH:mm:ss z yyyy</jb:decodeParam>
</jb:value>
(2.b) <jb:value property="customerNumber" data="header/customer/@number" />
(2.c) <jb:value property="customerName" data="header/customer" />
(2.d) <jb:expression property="total" execOnElement="order-item" >
+= (orderItem.price * orderItem.quantity);
</jb:expression>
</jb:bean>
(3) <jb:bean beanId="orderItems" class="java.util.ArrayList" createOnElement="order">
(3.a) <jb:wiring beanType="com.acme.OrderItem" /> <!-- Could also wire using beanIdRef="orderItem" -->
</jb:bean>
(4) <jb:bean beanId="orderItem" class="com.acme.OrderItem" createOnElement="order-item">
(4.a) <jb:value property="productId" data="order-item/product" />
(4.b) <jb:value property="quantity" data="order-item/quantity" />
(4.c) <jb:value property="price" data="order-item/price" />
</jb:bean>
</smooks-resource-list>| (1) |
Configuration (1) defines the creation rules for the com.acme.Order bean instance (top level bean). We create this bean instance at the very start of the message i.e. on the <order> element . In fact, we create each of the beans instances ((1), (2), (3) - all accepts (4)) at the very start of the message (on the <order> element). We do this because there will only ever be a single instance of these beans in the populated model.
Configurations (1.a) and (1.b) define the wiring configuration for wiring the Header and List<OrderItem> bean instances ((2) and (3)) into the Order bean instance (see the beanIdRef attribute values and how the reference the beanId values defined on (2) and (3)). The property attributes on (1.a) and (1.b) define the Order bean properties on which the wirings are to be made. Note also that beans can also be wired into an object based on their Java class type (beanType), or by being annotated with a specific Annotation (beanAnnotation). |
| (2) |
Configuration (2) creates the com.acme.Header bean instance.
Configuration (2.a) defines a value binding onto the Header.date property. Note that the data attribute defines where the binding value is selected from the source message; in this case it is coming from the header/date element. Also note how it defines a decodeParam sub-element. This configures the DateDecoder. Configuration (2.b) defines a value binding configuration onto Header.customerNumber property. What should be noted here is how to configure the data attribute to select a binding value from an element attribute on the source message. Configuration (2.b) also defines an expression binding where the order total is calculated and set on the Header.total property. The execOnElement attribute tells Smooks that this expression needs to be evaluated (and bound/rebound) on the order-item element. So, if there are multiple <order-item> elements in the source message, this expression will be executed for each <order-item> and the new total value rebound into the Header.total property. Note how the expression adds the current orderItem total to the current order total (header.total). Configuration (2.d) defines an expression binding, where a running total is calculated by adding the total for each order item (quantity * price) to the current total. |
| (3) |
Configuration (3) creates the List<OrderItem> bean instance for holding the OrderItem instances.
Configuration (3.a) wires all beans of type com.acme.OrderItem ( i.e. (4)) into the list. Note how this wiring does not define a property attribute. This is because it wires into a Collection (same applies if wiring into an array). Also note that we could have performed this wiring using the beanIdRef attribute instead of the beanType attribute. |
| (4) |
Configuration (4) creates the OrderItem bean instances. Note how the createOnElement is set to the <order-item> element. This is because we want a new instance of this bean to be created for every <order-item> element (and wired into the List<OrderItem> (3.a)).
If the createOnElement attribute for this configuration was not set to the <order-item> element (e.g. if it was set to one of the <order>, <header> or <order-items> elements), then only a single OrderItem bean instance would be created and the binding configurations ((4.a) etc) would overwrite the bean instance property bindings for every <order-item> element in the source message i.e. you would be left with a List<OrderItem> with just a single OrderItem instance containing the <order-item> data from the last <order-item> encountered in the source message. |
Binding Tips
-
<jb:bean createOnElement>-
Set it to the root element (or
#document): For bean instances where only a single instance will exist in the model. -
Set it to the recurring element: For Collection bean instances. If you don’t specify the correct element in this case, you could loose data.
-
-
<jb:value decoder>-
In most cases, Smooks will automatically detect the datatype decoder to be used for a
<jb:value>binding. However, some decoders require configuration e.g. the DateDecoder (decoder="Date"). In these cases, the decoder attribute should be defined on the binding, as well as the <jb:decodeParam> child elements for specifying the decode parameters for that decoder. See the full list of DataDecoder available out-of-the-box.
-
-
<jb:wiring property>-
Not required when binding into Collections.
-
-
Collections
-
Just define the to be the required Collection type and wire in the Collection entries.
-
For arrays, just postfix the attribute value with square brackets e.g.
class="com.acme.OrderItem[]".
-
Type Converters
In most cases, Smooks will automatically detect the datatype type converter to be used for a given <jb:value> binding. However, some decoders require configuration e.g. the TypeConverter (decoder="Date").In these cases, the converter attribute should be defined on the binding, as well as the <jb:decodeParam> child elements for specifying the decode parameters for that converter.
A number of date-based type converter implementations are available:
-
Date: Decode/Encode a String to a java.util.Date instance.
-
Calendar: Decode/Encode a String to a java.util.Calendar instance.
-
SqlDate: Decode/Encode a String to a java.sql.Date instance.
-
SqlTime: Decode/Encode a String to a java.sql.Time instance.
-
SqlTimestamp: Decode/Encode a String to a java.sql.Timestamp instance.
All of these date-based type converter implementations are configured in the same way.
Date Example:
<jb:value property="date" decoder="Date" data="order/@date">
<jb:decodeParam name="format">EEE MMM dd HH:mm:ss z yyyy</jb:decodeParam>
<jb:decodeParam name="locale">sv_SE</jb:decodeParam>
</jb:value>SqlTimestamp Example:
<jb:value property="date" decoder="SqlTimestamp" data="order/@date">
<jb:decodeParam name="format">EEE MMM dd HH:mm:ss z yyyy</jb:decodeParam>
<jb:decodeParam name="locale">sv</jb:decodeParam>
</jb:value>The format decodeParam is based on the ISO 8601 standard for Date formatting. See SimpleDateFormat Javadoc and Wikipedia for more information.
The locale decodeParam value is an underscore separated string, with the first token being the ISO Language Code for the Locale and the second token being the ISO Country Code. This decodeParam can also be specified as 2 separate parameters for language and country e.g.:
<jb:value property="date" decoder="Date" data="order/@date">
<jb:decodeParam name="format">EEE MMM dd HH:mm:ss z yyyy</jb:decodeParam>
<jb:decodeParam name="locale-language">sv</jb:decodeParam>
<jb:decodeParam name="locale-country">SE</jb:decodeParam>
</jb:value>A number of Number based type converter implementations are available:
-
BigDecimalDecoder: Decode/Encode a String to a java.math. BigDecimal instance.
-
BigIntegerDecoder: Decode/Encode a String to a java.math. BigInteger instance.
-
DoubleDecoder: Decode/Encode a String to a java.lang.Double instance (including primitive).
-
FloatDecoder: Decode/Encode a String to a java.lang.Float instance (including primitive).
-
IntegerDecoder: Decode/Encode a String to a java.lang.Integer instance (including primitive).
-
LongDecoder: Decode/Encode a String to a java.lang.Long' instance (including primitive).
-
ShortDecoder: Decode/Encode a String to a java.lang.Short instance (including primitive).
All of these Number based type converter implementations are configured in the same way.
BigDecimal Example:
<jb:value property="price" decoder="BigDecimal" data="orderItem/price">
<jb:decodeParam name="format">#,###.##</jb:decodeParam>
<jb:decodeParam name="locale">en_IE</jb:decodeParam>
</jb:value>Integer Example:
<jb:value property="percentage" decoder="Integer" data="vote/percentage">
<jb:decodeParam name="format">#%</jb:decodeParam>
</jb:value>The format decodeParam is based on the NumberFormat pattern syntax.
The locale decodeParam value is an underscore separated string, with the first token being the ISO Language Code for the Locale and the second token being the ISO Country Code. This decodeParam can also be specified as 2 separate parameters for language and country e.g.,:
<jb:value property="price" decoder="Double" data="orderItem/price">
<jb:decodeParam name="format">#,###.##</jb:decodeParam>
<jb:decodeParam name="locale-language">sv</jb:decodeParam>
<jb:decodeParam name="locale-country">SE</jb:decodeParam>
</jb:value>Sometimes you want to bind a different value into your object model, based on the data in your input message. You could use an expression based binding to do this, but you could also use a Mapping type converter as follows:
<jb:value property="name" decoder="Mapping" data="history/@warehouse">
<jb:decodeParam name="1">Dublin</jb:decodeParam>
<jb:decodeParam name="2">Belfast</jb:decodeParam>
<jb:decodeParam name="3">Cork</jb:decodeParam>
</jb:value>In the above example, an input data value of "1" is mapped onto the "name" property as a value of "Dublin". Likewise for values "2" and "3".
The Enum type converter is a specialized version of the Mapping type converter. Decoding of enumerations will typically happen automatically (without any specific configuration) if the data input values map exactly to the enum values/names. However when this is not the case, you need to define mappings from the input data value to the enum value/name.
In the following example, the header/priority field in the input message contains values of LOW, MEDIUM and HIGH. This need to be mapped the example.trgmodel.LineOrderPriority enum values of NOT_IMPORTANT, IMPORTANT and VERY_IMPORTANT respectfully:
<jb:value property="priority" data="header/priority" decoder="Enum">
<jb:decodeParam name="enumType">example.trgmodel.LineOrderPriority</jb:decodeParam>
<jb:decodeParam name="LOW">NOT_IMPORTANT</jb:decodeParam>
<jb:decodeParam name="MEDIUM">IMPORTANT</jb:decodeParam>
<jb:decodeParam name="HIGH">VERY_IMPORTANT</jb:decodeParam>
</jb:value>Note that if mappings are required, you must also explicitly specify the enumeration type using the enumType decodeParam.
Bean Retention
By default, all but the first bean configured in the Smooks configuration are removed from the BeanContext after the fragment that created the bean (createOnElement) is processed i.e. the bean is added to the BeanContext on the start/visitBefore of the createOnElement fragment, and is removed from the bean context at the end/visitAfter. By default, this rule applies to all but the first bean configured in the Smooks configuration i.e. by default, the first bean is the only bean that is retained in the BeanContext, and so can be accessed after the message has been processed.
To change this default behavior, use the retain configuration attribute on the <jb:bean> element. This attribute allows you to manually control bean retention within the Smooks BeanContext.
Preprocessing Binding Values
The Java Bean cartridge works by:
-
Extracting String values from the source/input message stream.
-
Decoding the String value based on the "decoder" and "decodeParam" configurations (note that, if not defined, an attempt is made to reflectively resolve the decoder).
-
The decoded value is set on the target bean.
Sometimes it is necessary to perform some rudimentary "pre-processing" on the String data value before the decode step (between steps #1 and #2 above). An example of this might be where the source data has some characters not supported by the locale configuration on Numeric Decoding e.g. the numeric value 876592.00 might be represented as "876_592!00" (who knows why). In order to decode this value as (for example) a double value, we need to eliminate the underscore and exclamation mark characters, replacing the exclamation mark with a period i.e. we need to convert it to "876592.00" before decoding.
One way of doing this is to write a custom DataDecoder implementation (which is recommended if it’s a recurring decoding operation), but if you need a quick-n-dirty solution, you can specify a valuePreprocess, which is a simple expression to be applied to the Sting value before decoding.
As an example for solving the numeric decoding issue described above:
<!-- A bean property binding example: -->
<jb:bean beanId="orderItem" class="org.smooks.javabean.OrderItem" createOnElement="price">
<jb:value property="price" data="price" decoder="Double">
<jb:decodeParam name="valuePreprocess">value.replace("_", "").replace("!", ".")</jb:decodeParam>
</jb:value>
</jb:bean><!-- A direct value binding example: -->
<jb:value beanId="price" data="price" decoder="BigDecimal">
<jb:decodeParam name="valuePreprocess">value.replace("_", "").replace("!", ".")</jb:decodeParam>
</jb:value>Note in the above example how the String data value is referenced in the expression using the value variable name. The expression can be any valid MVEL expression that operates on the value String and returns a String.
Creating Beans Using a Factory
The Java Bean cartridge supports factories for creating the beans. In that case you don’t need a public parameterless constructor. You don’t even have to define the actual class name in the class attribute. Any of the interfaces of the object suffices. However only the methods of that interface are available for binding to. So even if you define a factory, you must always set the class attribute in the bean definition.
The factory definition is set in the factory attribute of the bean element. The default factory definition language looks like this:
The default factory definition language looks like this:
some.package.FactoryClass#staticMethod{.instanceMethod}This basic definition language enables you to define a static public parameterless method that Smooks should call to create the bean. The 'instanceMethod part is optional. If it is set it defines the method that will be called on the object that is returned from static method, which should create the bean (The { } chars only illustrates the part that is optional and should be left out of the actual definition!).
Here is an example where we instantiate an ArrayList object using a static factory method:
<jb:bean beanId="orders"
class="java.util.List"
factory="some.package.ListFactory#newList"
createOnElement="orders">
<!-- ... bindings -->
</jb:bean>The factory definition "some.package.ListFactory#newList" defines that the newList method must be called on the "some.package.ListFactory" class for creating the bean. The class attributes defines that the bean is a List object. What kind of List object (ArrayList, LinkedList) is up to the ListFactory to decide. Here is another example:
<jb:bean beanId="orders"
class="java.util.List"
factory="some.package.ListFactory#getInstance.newList"
createOnElement="orders">
<!-- ... bindings -->
</jb:bean>Here we defined that an instance of the ListFactory needs to be retrieved using the static method getInstance and that then the newList method needs to be called on the ListFactory object to create the List object. This construct makes it possible to easily use Singleton Factories.
You can use a different definition language then the default basic language. For instance you can use MVEL as the factory definition language.
There are three methods to declare which definition language you want to use:
-
Each definition language can have an alias. For instance MVEL has the alias 'mvel'. To define that you want to use MVEL for a specific factory definition you put 'mvel:' in front of the definition. e.g.
mvel:some.package.ListFactory.getInstance().newList(). The alias of the default basic language is 'basic'. -
To set a language as a global default you need to set the ‘factory.definition.parser.class’ global parameter to the full class path of the class that implements the FactoryDefinitionParser interface for the language that you want to use.
If you have a definition with your default language that includes a ':' then you must prefix that definition with 'default:' else you will run into an Exception. -
Instead of using an alias you can also set the full class path of the class that implements the FactoryDefinitionParser interface for the language that you want to use. e.g. 'org.smooks.javabean.factory.MVELFactoryDefinitionParser:some.package.ListFactory.getInstance().newList()'. You probably only should use this for test purposes only. It is much better to define an alias for your language.
If you want to define your own language then you need to implement the org.smooks.javabean.factory.FactoryDefinitionParser interface. Take a look at the org.smooks.javabean.factory.MVELFactoryDefinitionParser or org.smooks.javabean.factory.BasicFactoryDefinitionParser for a good example.
To define the alias for a definition language you need to add the 'org.smooks.javabean.factory.Alias' annotation with the alias name to your FactoryDefinitionParser class.
For Smooks to find your alias you need create the file 'META-INF/smooks-javabean-factory-definition-parsers.inf' on the root of your classpath. This file must contain the full class path of all the files that implement the FactoryDefinitionParser interface having the Alias annotation (separated by new lines).
MVEL as factory definition language
MVEL has some advantages over the basic default definition language, for example you can use objects from the bean context as the factory object or you can call factory methods with parameters. These parameters can be defined within the definition or they can be objects from the bean context. To be able to use MVEL use the alias mvel or you can set the factory.definition.parser.class global parameter to org.smooks.javabean.factory.MVELFactoryDefinitionParser.
Here is an example with the same use case as before but then with MVEL:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<jb:bean beanId="orders" class="java.util.List" factory="mvel:some.package.ListFactory.getInstance().newList()"
createOnElement="orders">
<!-- ... bindings -->
</jb:bean>
</smooks-resource-list>In the next example we use MVEL to extract a List object from an existing bean in the bean context. The Order object in this example has method that returns a list which we must use to add the order lines to:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd" xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<jb:bean beanId="order" class="some.package.Order" createOnElement="order">
<!-- ... bindings -->
</jb:bean>
<!--
The factory attribute uses MVEL to access the order
object in the bean context and calls its getOrderLines()
method to get the List. This list is then added to the bean
context under the beanId 'orderLines'
-->
<jb:bean beanId="orderLines" class="java.util.List" factory="mvel:order.getOrderLines()" createOnElement="order">
<jb:wiring beanIdRef="orderLine" />
</jb:bean>
<jb:bean beanId="orderLine" class="java.util.List" createOnElement="order-line">
<!-- ... bindings -->
</jb:bean>
</smooks-resource-list>Maybe you wonder why we don’t use MVEL as the default factory definition language? Currently the performance of the basic definition language and MVEL are about equal. The reason that the basic definition language isn’t faster is because it currently uses reflection to call the factory methods. However there are plans to use byte code generation instead of reflection. This should improve the performance dramatically. If MVEL where the default language then we couldn’t do anything to improve the performance for those people who don’t need any thing more than the basic features that the basic definition language offers.
Array objects are not supported. If a factory return an array then Smooks will throw an exception at some point.
Binding Key Value Pairs into Maps
If the attribute of a binding is not defined (or is empty), then the name of the selected node will be used as the map entry key (where the beanClass is a Map).
There is one other way to define the map key. The value of the attribute can start with the @ character. The rest of the value then defines the attribute name of the selected node, from which the map key is selected. The following example demonstrates this:
<root>
<property name="key1">value1</property>
<property name="key2">value2</property>
<property name="key3">value3</property>
</root>And the config:
<jb:bean beanId="keyValuePairs" class="java.util.HashMap" createOnElement="root">
<jb:value property="@name" data="root/property" />
</jb:bean>This would create a HashMap with three entries with the keys set [key1, key2, key3].
Of course the @ the character notation doesn’t work for bean wiring. The cartridge will simply use the value of the property attribute, including the @ character, as the map entry key.
Virtual Object Models (Maps & Lists)
It is possible to create a complete object model without writing your own Bean classes. This virtual model is created using only maps and lists . This is very convenient if you use the javabean cartridge between two processing steps. For example, as part of a model driven transform e.g. xml→java→xml or xml→java→edi.
The following example demonstrates the principle:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd" xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.0.xsd">
<!--
Bind data from the message into a Virtual object model in the bean context....
-->
<jb:bean beanId="order" class="java.util.HashMap" createOnElement="order">
<jb:wiring property="header" beanIdRef="header" />
<jb:wiring property="orderItems" beanIdRef="orderItems" />
</jb:bean>
<jb:bean beanId="header" class="java.util.HashMap" createOnElement="order">
<jb:value property="date" decoder="Date" data="header/date">
<jb:decodeParam name="format">EEE MMM dd HH:mm:ss z yyyy</jb:decodeParam>
</jb:value>
<jb:value property="customerNumber" decoder="Long" data="header/customer/@number" />
<jb:value property="customerName" data="header/customer" />
<jb:expression property="total" execOnElement="order-item" >
header.total + (orderItem.price * orderItem.quantity);
</jb:expression>
</jb:bean>
<jb:bean beanId="orderItems" class="java.util.ArrayList" createOnElement="order">
<jb:wiring beanIdRef="orderItem" />
</jb:bean>
<jb:bean beanId="orderItem" class="java.util.HashMap" createOnElement="order-item">
<jb:value property="productId" decoder="Long" data="order-item/product" />
<jb:value property="quantity" decoder="Integer" data="order-item/quantity" />
<jb:value property="price" decoder="Double" data="order-item/price" />
</jb:bean>
<!--
Use a FreeMarker template to perform the model driven transformation on the Virtual Object Model...
-->
<ftl:freemarker applyOnElement="order">
<ftl:template>/templates/orderA-to-orderB.ftl</ftl:template>
</ftl:freemarker>
</smooks-resource-list>Note above how we always define the decoder attribute for a Virtual Model (Map). This is because Smooks has no way of auto-detecting the decode type for data binding to a Map. So, if you need typed values bound into your Virtual Model, you need to specify an appropriate decoder. If the decoder is not specified in this case, Smooks will simply bind the data into the Virtual Model as a String.
Take a look at the model-driven-basic and model-driven-basic-virtual examples.
Virtual models also support "wildcard" bindings. That is, you can bind all the child elements of an element into a Map using a single configuration, where the child element names act as the Map entry key and the child element text value acts as the Map entry value. To do this, you simply omit the property attribute from the configuration and use a wildcard in the data attribute.
In the following example, we have a element containing some values that we wish to populate into a Map.
<order-item>
<product>111</product>
<quantity>2</quantity>
<price>8.90</price>
</order-item>The wildcard binding config for doing this would be:
<jb:bean beanId="orderItem" class="java.util.HashMap" createOnElement="order-items/orderItem">
<jb:value data="order-items/orderItem/*" />
</jb:bean>This will result in the creation of an "orderItem" Map bean instance containing entries [product=111], [quantity=2] and [price=8.90].
Merging Multiple Data Entities Into a Single Binding
This can be achieved using Expression Based Bindings (<jb:expression>).
Direct Value Binding
Direct value binding uses the Smooks TypeConverter to create an object from a selected data element/attribute and add it directly to the bean context. The org.smooks.cartridges.javabean.ValueBinder class is the visitor binding the value.
The value binding XML configuration is part of the JavaBean schema from Smooks 1.3 on:
https://www.smooks.org/xsd/smooks/javabean-1.6.xsd. The element for the value binding is <value>.
The <value> has the following attributes:
-
beanId: The ID under which the created object is to be bound in the bean context. -
data: The data selector for the data value to be bound. e.g.order/orderidororder/header/@date -
dataNS: The namespace for thedataselector -
decoder: The DataDecoder name for converting the value from a String into a different type. The DataDecoder can be configured with the elements. -
default: The default value for if the selected data is null or an empty string.
Taking the classic Order message as an example and getting the order number, name and date as Value Objects in the form of an Integer and String.
Message
<order xmlns="http://x">
<header>
<y:date xmlns:y="http://y">Wed Nov 15 13:45:28 EST 2006</y:date>
<customer number="123123">Joe</customer>
<privatePerson></privatePerson>
</header>
<order-items>
<!-- .... -->
</order-items>
</order>Configuration
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<jb:value beanId="customerName" data="customer" default="unknown"/>
<jb:value beanId="customerNumber" data="customer/@number" decoder="Integer"/>
<jb:value beanId="orderDate" data="date" dateNS="http://y" decoder="Date">
<jb:decodeParam name="format">EEE MMM dd HH:mm:ss z yyyy</jb:decodeParam>
<jb:decodeParam name="locale-language">en</jb:decodeParam>
<jb:decodeParam name="locale-country">IE</jb:decodeParam>
</jb:value>
</smooks-resource-list>The value binder can be programmatic configured using the org.smooks.javabean.Value Object.
Example
We use the same example message as the XML configuration example.
//Create Smooks. normally done globally!
Smooks smooks = new Smooks();
//Create the Value visitors
Value customerNumberValue = new Value( "customerNumber", "customer/@number").setDecoder("Integer");
Value customerNameValue = new Value( "customerName", "customer").setDefault("Unknown");
//Add the Value visitors
smooks.addVisitors(customerNumberValue);
smooks.addVisitors(customerNameValue);
//And the execution code:
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(orderMessageStream), sink);
Integer customerNumber = (Integer) sink.getBean("customerNumber");
String customerName = (String) sink.getBean("customerName");Programmatic Configuration
Java Binding Configuratons can be programmatically added to a Smooks using the Bean configuration class.
This class can be used to programmatically configure a Smooks instance for performing a Java Bindings on a specific class. To populate a graph, you simply create a graph of Bean instances by binding Beans onto Beans. The Bean class uses a Fluent API (all methods return the Bean instance), making it easy to string configurations together to build up a graph of Bean configuration.
Example
Taking the classic Order message as an example and binding it into a corresponding Java object model.
The Message:
<order xmlns="http://x">
<header>
<y:date xmlns:y="http://y">Wed Nov 15 13:45:28 EST 2006</y:date>
<customer number="123123">Joe</customer>
<privatePerson></privatePerson>
</header>
<order-items>
<order-item>
<product>111</product>
<quantity>2</quantity>
<price>8.90</price>
</order-item>
<order-item>
<product>222</product>
<quantity>7</quantity>
<price>5.20</price>
</order-item>
</order-items>
</order>The Java Model (not including getters/setters):
public class Order {
private Header header;
private List<OrderItem> orderItems;
}
public class Header {
private Long customerNumber;
private String customerName;
}
public class OrderItem {
private long productId;
private Integer quantity;
private double price;
}The Configuration Code:
Smooks smooks = new Smooks();
Bean orderBean = new Bean(Order.class, "order", "/order");
orderBean.bindTo("header",
orderBean.newBean(Header.class, "/order")
.bindTo("customerNumber", "header/customer/@number")
.bindTo("customerName", "header/customer")
).bindTo("orderItems",
orderBean.newBean(ArrayList.class, "/order")
.bindTo(orderBean.newBean(OrderItem.class, "order-item")
.bindTo("productId", "order-item/product")
.bindTo("quantity", "order-item/quantity")
.bindTo("price", "order-item/price"))
);
smooks.addVisitors(orderBean);The Execution Code:
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(orderMessageStream), sink);
Order order = (Order) sink.getBean("order");The API supports factories. You can provide a factory object of the type org.smooks.javabean.factory.Factory, that will be called when a new bean instance needs to be created.
Here is an example where an anonymous Factory class is defined and used:
Bean orderBean = new Bean(Order.class, "order", "/order", new Factory<Order>() {
public Order create(ExecutionContext executionContext) {
return new Order();
}
});XML to Java Reading and Writing
The XMLBinding class is a special utility wrapper class around the Smooks runtime. It was introduced in Smooks v1.5 and it is designed specifically for reading and writing XML data to and from Java object models using nothing more than standard configurations i.e. no need to write a template for serializing the Java objects to an output character based format, as with Smooks v1.4 and before.
So basically, this functionality allows you to do what you can do with frameworks like JAXB or JiBX i.e. read *and write* between Java and XML using a single configuration, but with the added advantage of being able to easily handle multiple versions of an XML schema/model in a single Java model. You can read and write multiple versions of an XML message into a single/common Java object model. This is very useful in itself, but also means you can easily transform messages from one version to another by reading the XML into the common Java object model using an XMLBinding instance configured for one version of the XML, and then writing those Java objects back out using an XMLBinding instance configured for the other version of the XML.
Simple XMLBinding Use Case
Using the XMLBinding class is really easy. You:
-
write a standard Smooks Java Binding Configuration,
-
addit to the XMLBinding instance, -
initializethe XMLBinding instance, -
call the
fromXMLandtoXMLmethods on the XMLBinding instance.
// Create and initialize the XMLBinding instance...
XMLBinding xmlBinding = new XMLBinding().add("/smooks-configs/order-xml-binding.xml");
xmlBinding.initialize();
// Read the order XML into the Order object model...
Order order = xmlBinding.fromXML(new StreamSource(inputReader), Order.class);
// Do something with the order....
// Write the Order object model instance back out to XML...
xmlBinding.toXML(order, outputWriter);See the xml-read-write example.
Transforming XML Messages Using XMLBinding
As stated above, one of the more powerful capabilities of the XMLBinding class is its ability to read and write multiple versions/formats of a given message into a single common Java object model. By extensions, this means that you can use it to transform messages from one version to another by reading the XML into the common Java object model using an XMLBinding instance configured for one version of the XML, and then writing those Java objects back out using an XMLBinding instance configured for the other version of the XML.
// Create and initilise the XMLBinding instances for v1 and v2 of the XMLs...
XMLBinding xmlBindingV1 = new XMLBinding().add("v1-binding-config.xml");
XMLBinding xmlBindingV2 = new XMLBinding().add("v2-binding-config.xml");
xmlBindingV1.intiailize();
xmlBindingV2.intiailize();
// Read the v1 order XML into the Order object model...
Order order = xmlBindingV1.fromXML(new StreamSource(inputReader), Order.class);
// Write the Order object model instance back out to XML using the v2 XMLBinding instance...
xmlBindingV2.toXML(order, outputWriter);See the xml-read-write-transform example.
Generating the Smooks Binding Configuration
The JavaBean Cartridge contains the org.smooks.javabean.gen.ConfigGenerator utility class that can be used to generate a binding configuration template. This template can then be used as the basis for defining a binding.
From the commandline:
$JAVA_HOME/bin/java -classpath org.smooks.javabean.gen.ConfigGenerator -c -o [-p ]-
The
-ccommandline arg specifies the root class of the model whose binding config is to be generated. -
The
-ocommandline arg specifies the path and filename for the generated config output. -
The
-pcommandline arg specifies the path and filename optional binding configuration file that specifies additional binding parameters.
The optional -p properties file parameter allows specification of additional config parameters:
-
packages.included: Semi-colon separated list of packages. Any fields in the class matching these packages will be included in the binding configuration generated. -
packages.excluded: Semi-colon separated list of packages. Any fields in the class matching these packages will be excluded from the binding configuration generated.
After running this utility against the target class, you typically need to perform the following follow-up tasks in order to make the binding configuration work for your Source data model.
-
For each
<jb:bean>element, set thecreateOnElementattribute to the event element that should be used to create the bean instance. -
Update the
<jb:value data>attributes to select the event element/attribute supplying the binding data for that bean property. -
Check the
<jb:value decoder>attributes. Not all will be set, depending on the actual property type. These must be configured by hand e.g. you may need to configure<jb:decodeParam>sub-elements for the decoder on some of the bindings. E.g. for a date field. -
Double-check the binding config elements (
<jb:value>and<jb:wiring>), making sure all Java properties have been covered in the generated configuration.
Determining the selector values can sometimes be difficult, especially for non-XML Sources (Java, etc…). The Html Reporting tool can be a great help here because it helps you visualise the input message model (against which the selectors will be applied) as seen by Smooks. So, first off, generate a report using your Source data, but with an empty transformation configuration. In the report, you can see the model against which you need to add your configurations. Add the configurations one at a time, rerunning the report to check they are being applied.
The following is an example of a generated configuration. Note the $TODO$ tokens.
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<jb:bean beanId="order" class="org.smooks.javabean.Order" createOnElement="$TODO$">
<jb:wiring property="header" beanIdRef="header" />
<jb:wiring property="orderItems" beanIdRef="orderItems" />
<jb:wiring property="orderItemsArray" beanIdRef="orderItemsArray" />
</jb:bean>
<jb:bean beanId="header" class="org.smooks.javabean.Header" createOnElement="$TODO$">
<jb:value property="date" decoder="$TODO$" data="$TODO$" />
<jb:value property="customerNumber" decoder="Long" data="$TODO$" />
<jb:value property="customerName" decoder="String" data="$TODO$" />
<jb:value property="privatePerson" decoder="Boolean" data="$TODO$" />
<jb:wiring property="order" beanIdRef="order" />
</jb:bean>
<jb:bean beanId="orderItems" class="java.util.ArrayList" createOnElement="$TODO$">
<jb:wiring beanIdRef="orderItems_entry" />
</jb:bean>
<jb:bean beanId="orderItems_entry" class="org.smooks.javabean.OrderItem" createOnElement="$TODO$">
<jb:value property="productId" decoder="Long" data="$TODO$" />
<jb:value property="quantity" decoder="Integer" data="$TODO$" />
<jb:value property="price" decoder="Double" data="$TODO$" />
<jb:wiring property="order" beanIdRef="order" />
</jb:bean>
<jb:bean beanId="orderItemsArray" class="org.smooks.javabean.OrderItem[]" createOnElement="$TODO$">
<jb:wiring beanIdRef="orderItemsArray_entry" />
</jb:bean>
<jb:bean beanId="orderItemsArray_entry" class="org.smooks.javabean.OrderItem" createOnElement="$TODO$">
<jb:value property="productId" decoder="Long" data="$TODO$" />
<jb:value property="quantity" decoder="Integer" data="$TODO$" />
<jb:value property="price" decoder="Double" data="$TODO$" />
<jb:wiring property="order" beanIdRef="order" />
</jb:bean>
</smooks-resource-list>Notes on JavaSink
Users should note that there is no guarantee as to the exact contents of a JavaSink instance after calling the Smooks.filterSource method. After calling this method, the JavaSink instance will contain the final contents of the bean context, which can be added to by any visitor.
You can restrict the Bean set returned in a JavaSink by using a <jb:result> configuration in the Smooks configuration. In the following example configuration, we tell Smooks to only retain the "order" bean in the ResultSet:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<!-- Capture some data from the message into the bean context... -->
<jb:bean beanId="order" class="com.acme.Order" createOnElement="order">
<jb:value property="orderId" data="order/@id"/>
<jb:value property="customerNumber" data="header/customer/@number"/>
<jb:value property="customerName" data="header/customer"/>
<jb:wiring property="orderItems" beanIdRef="orderItems"/>
</jb:bean>
<jb:bean beanId="orderItems" class="java.util.ArrayList" createOnElement="order">
<jb:wiring beanIdRef="orderItem"/>
</jb:bean>
<jb:bean beanId="orderItem" class="com.acme.OrderItem" createOnElement="order-item">
<jb:value property="itemId" data="order-item/@id"/>
<jb:value property="productId" data="order-item/product"/>
<jb:value property="quantity" data="order-item/quantity"/>
<jb:value property="price" data="order-item/price"/>
</jb:bean>
<!-- Only retain the "order" bean in the root of any final JavaSink. -->
<jb:result retainBeans="order"/>
</smooks-resource-list>So after applying this configuration, calls to the JavaSink.getBean(String) method for anything other than the "order" bean will return null. This will work fine in cases such as the above example, because the other bean instances are wired into the "order" graph.
Note that as of Smooks v1.2, if a JavaSource instance is supplied to the Smooks#filterSource method (as the filter Source instance), Smooks will use the JavaSource to construct the bean context associated with the ExecutionContext for that Smooks.filterSource invocation. This will mean that some JavaSource bean instances may be visible in the JavaSink.
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-javabean-cartridge</artifactId>
<version>2.0.3</version>
</dependency>XML Namespace
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd"
JSON
Processing JSON with Smooks requires a JSON reader to be configured:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:json="https://www.smooks.org/xsd/smooks/json-1.3.xsd">
<json:reader/>
</smooks-resource-list>The XML element name of the root element, the element name of document and the element name of array elements can be configured with the following configuration options:
-
rootName: The name of the root element. Default:json. -
arrayElementName: The name of a sequence element. Default:element.
JSON allows characters in the key name that aren’t allowed in XML element name. To workaround that problem the reader offers multiple solutions. The JSON reader can search and replace whitespaces, illegal characters and the number in key names that start with a number. It is also possible to replace one key name with a completely different name. The following example demonstrates all these features:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:json="https://www.smooks.org/xsd/smooks/json-1.3.xsd">
<json:reader keyWhitspaceReplacement="_" keyPrefixOnNumeric="n" illegalElementNameCharReplacement=".">
<json:keyMap>
<json:key from="some key">someKey</json:key>
<json:key from="some&key" to="someAndKey"/>
</json:keyMap>
</json:reader>
</smooks-resource-list>-
keyWhitspaceReplacement: The replacement character for whitespaces in a json map key. By default this not defined, so that the reader doesn’t search for white spaces. -
keyPrefixOnNumeric: The prefix character to add if the JSON node name starts with a number. By default this is not defined, so that the reader doesn’t search for element names that start with a number. -
illegalElementNameCharReplacement: If illegal characters are encountered in a JSON element name then they are replaced with this value.
The following options can also be configured on the JSON reader:
-
nullValueReplacement: The replacement string for JSON NULL values. Default is an empty string. -
encoding: The default encoding of any JSON message InputStream processed by this Reader. Default of 'UTF-8'.
You shouldn’t need this configuration parameter and it will be removed in a future release. Instead, you should manage the JSON stream Source character encoding by supplying a java.io.Reader to the Smooks.filterSource() method.
|
Java API
Smooks is programmatically configured to read a JSON configuration using the JSONReaderConfigurator class.
Smooks smooks = new Smooks();
smooks.setReaderConfig(new JSONReaderConfigurator()
.setRootName("root")
.setArrayElementName("e"));
// Use Smooks as normal...
...Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-json-cartridge</artifactId>
<version>2.0.3</version>
</dependency>XML Namespace
xmlns:json="https://www.smooks.org/xsd/smooks/json-1.3.xsd"
Templating
Smooks Templating Cartridge supports the following template providers:
This cartridge adds the ability to use these templating technologies within the Smooks filtering process. This means that templates can:
-
Be applied to an input source on a per-fragment basis (e.g., for transformations) as opposed to the whole document. This could be useful in situations where you only wish to insert a piece of data into a stream at a specific position (e.g., add headers to a SOAP message) but do not wish to interfere with the rest of the stream. In this case, you can apply the template to the fragment of interest. This method of transformation is commonly known as enrichment.
-
Take advantage of other Smooks cartridges such as the JavaBean cartridge. You can use the JavaBean cartridge to (1) decode and bind the stream data to the Smooks bean context, and then (2) reference that decoded data from within your FreeMarker template.
-
Be used to process huge message streams (e.g., gigabytes), while at the same time maintain a relatively simple processing model, with a low memory footprint. See Processing Huge Messages for further information.
-
Be used for generating new fragments that can then be routed (using Smooks Routing components) to physical endpoints (e.g., File, JMS), or logical endpoints on an ESB (a "Service").
Smooks can be extended to support other templating technologies.
| Be sure to read the section on Java Binding. |
FreeMarker Templating
FreeMarker is a powerful templating engine. Smooks uses FreeMarker to create text from a fragment. This text can then be inserted into the result stream, or routed to another process.
Add the schema declaration https://www.smooks.org/xsd/smooks/freemarker-2.1.xsd to the Smooks XML config to configure FreeMarker resources with namespace elements.
Example - Inline Template:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.1.xsd">
<ftl:freemarker applyOnElement="order">
<ftl:template><!--<orderId>${order.id}</orderId>--></ftl:template>
</ftl:freemarker>
</smooks-resource-list>Example - External Template Reference:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.1.xsd">
<ftl:freemarker applyOnElement="order">
<ftl:template>/templates/shop/ordergen.ftl</ftl:template>
</ftl:freemarker>
</smooks-resource-list>FreeMarker transformations using node trees
The easiest way to construct message transformations in FreeMarker is to leverage FreeMarker’s DOM tree facility. This is where FreeMarker uses a W3C DOM for node variables, referencing the DOM nodes directly from inside the FreeMarker template. Smooks extends this by:
-
Capturing DOM nodes on a fragment-basis: you do not have to use the full document for the DOM model, just the targeted fragment.
-
Allowing the captured DOM nodes node trees to be referenced from Freemarker templates during filtering to create non-XML messages like CSV and JSON.
To take advantage of this facility in Smooks, you need to configure a org.smooks.engine.resource.visitor.dom.DomModelCreator resource that declares the node trees to be captured:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.1.xsd">
<!--
Create a pipeline that replaces <order>...</order> with <salesorder>...</salesorder>. In this example, the total memory footprint is kept as low as possible. An <order> event will hold only the order ID and not the main bulk of data in the message (i.e., order-item elements). At any one time, Smooks will have just a single <order-item> in main memory.
-->
<core:smooks filterSourceOn="#document">
<core:action>
<core:inline>
<core:replace/>
</core:inline>
</core:action>
<core:config>
<smooks-resource-list>
<!--
Create 2 node trees. One model for the "customer" and then one
per "order-item".
These model are used in the FreeMarker templating resources
defined below. You need to make sure you set the selector such
that the total memory footprint is as low as possible. In this
example, the "customer" model will contain the customer name. The
"order-item" model only contains the current <order-item> data
(i.e., there's max 1 order-item in memory at any one time).
-->
<resource-config selector="customer,order-item">
<resource>org.smooks.engine.resource.visitor.dom.DomModelCreator</resource>
</resource-config>
<!--
Apply the first part of the template when we reach the start
of the <order> element.
-->
<ftl:freemarker applyOnElement="order" applyBefore="true">
<ftl:template><!--<salesorder>
<details>
<orderid>${order.@id}</orderid>
--> </ftl:template>
</ftl:freemarker>
<ftl:freemarker applyOnElement="header/customer">
<ftl:template><!-- <customer>
<id>${customer.@number}</id>
<name>${customer}</name>
</customer>
</details>
<itemList>--> </ftl:template>
</ftl:freemarker>
<!--
Output the <order-items> elements.
-->
<ftl:freemarker applyOnElement="order-item">
<ftl:template><!-- <item>
<id>${.vars["order-item"].@id}</id>
<productId>${.vars["order-item"].product}</productId>
<quantity>${.vars["order-item"].quantity}</quantity>
<price>${.vars["order-item"].price}</price>
</item>--> </ftl:template>
</ftl:freemarker>
<!--
Apply the last part of the template when we reach the end
of the <order> element.
-->
<ftl:freemarker applyOnElement="order">
<ftl:template><!--</itemList>
</salesorder>--> </ftl:template>
</ftl:freemarker>
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>FreeMarker and JavaBean Cartridge
FreeMarker node trees are very powerful and easy to use. The trade-off is performance. Constructing W3C DOMs is expensive. It also may be the case that the required data has already been extracted and populated into a Java object model (e.g., where the data also needs to be routed to a JMS endpoint as Java Objects).
In situations where using a node tree is not practical, Smooks allows you to use the JavaBean Cartridge to populate a POJO (or a Virtual Model). This model can then be referencing from the FreeMarker templated. See the docs on the JavaBean Cartridge for more details.
Example (using a Virtual Model):
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.1.xsd">
<!-- Extract and decode data from the message. Used in the freemarker template (below). -->
<jb:bean beanId="order" class="java.util.Hashtable" createOnElement="order">
<jb:value property="orderId" decoder="Integer" data="order/@id"/>
<jb:value property="customerNumber" decoder="Long" data="header/customer/@number"/>
<jb:value property="customerName" data="header/customer"/>
<jb:wiring property="orderItem" beanIdRef="orderItem"/>
</jb:bean>
<jb:bean beanId="orderItem" class="java.util.Hashtable" createOnElement="order-item">
<jb:value property="itemId" decoder="Integer" data="order-item/@id"/>
<jb:value property="productId" decoder="Long" data="order-item/product"/>
<jb:value property="quantity" decoder="Integer" data="order-item/quantity"/>
<jb:value property="price" decoder="Double" data="order-item/price"/>
</jb:bean>
<ftl:freemarker applyOnElement="order-item">
<ftl:template><!--<orderitem id="${order.orderItem.itemId}" order="${order.orderId}">
<customer>
<name>${order.customerName}</name>
<number>${order.customerNumber?c}</number>
</customer>
<details>
<productId>${order.orderItem.productId}</productId>
<quantity>${order.orderItem.quantity}</quantity>
<price>${order.orderItem.price}</price>
</details>
</orderitem>-->
</ftl:template>
</ftl:freemarker>
</smooks-resource-list>| See full example in the file-router example |
Programmatic Configuration
FreeMarker templating configurations can be programmatically added to a Smooks instance by configuring and adding a FreeMarkerTemplateProcessor instance to the Smooks instance. The following example creates a Smooks instance with Java binding and FreeMarker templating configurations:
Smooks smooks = new Smooks();
smooks.addVisitor(new Bean(OrderItem.class, "orderItem", "order-item").bindTo("productId", "order-item/product/@id"));
smooks.addVisitor(new FreeMarkerTemplateProcessor(new TemplatingConfiguration("/templates/order-tem.ftl")), "order-item");
// And then just use Smooks as normal... filter a Source to a Sink etc...XSLT Templating
Configuring XSL resources in Smooks is almost identical to that of configuring FreeMarker resources. Add the schema declaration https://www.smooks.org/xsd/smooks/xsl-2.0.xsd to the Smooks XML config to configure XSL resources with namespace elements.
Example:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:xsl="https://www.smooks.org/xsd/smooks/xsl-2.0.xsd">
<xsl:xsl applyOnElement="#document">
<xsl:template><!--<xxxxxx/>--></xsl:template>
</xsl:xsl>
</smooks-resource-list>As with a FreeMarker resource, an XSLT script can be externally referenced from the XSL resource.
As already stated, configuring XSLT templates in Smooks is almost identical to that of configuring FreeMarker templates (see above). For this reason, please consult the FreeMarker configuration docs. Translating to XSL counterparts is simply a matter of changing the configuration namespace. However, please read the following sections.
Points to note regarding XSLT support
-
It is not recommended to use Smooks for executing XSLT, unless:
-
You need to perform fragment transformations, in other words, you are not transforming the whole message.
-
You need to use other Smooks functionality to perform other operations on the input source, such as message splitting, persistence, etc…
-
-
Smooks applies XSLT scripts on a fragment-basis (i.e., DOM element nodes) instead of the whole document (i.e., DOM document node). This can be very useful for modularizing your XSLT scripts, however, one ought not to assume that an XSLT script written and working standalone (externally to Smooks and on the whole document) will behave as expected when called from Smooks without modification. The reason is that Smooks handles XSLT targeted at the document root node differently: Smooks applies the XSLT to the DOM document node instead of the root DOM element. You may need to tweak to the stylesheet if you already have XSLT scripts and are porting them to Smooks.
-
XSLT scripts typically contain a template matched to the root element. Because Smooks applies the XSLT on a fragment-basis, matching against the "root element" is no longer valid. You need to make sure the stylesheet contains a template that matches against the context node (i.e., the targeted fragment).
My XSLT works outside Smooks but not from within Smooks?
This can happen and is most likely going to be a result of your stylesheet containing a template that is using an absolute path reference to the document root node. This will cause issues in the Smooks fragment-based processing model because the element being targeted by Smooks is not the document root node. Your XSLT needs to contain a template that matches against the context node being targeted by Smooks.
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-templating-cartridge</artifactId>
<version>2.1.2</version>
</dependency>YAML
Processing YAML with Smooks requires a YAML reader to be configured:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:yaml="https://www.smooks.org/xsd/smooks/yaml-1.5.xsd">
<yaml:reader/>
</smooks-resource-list>YAML stream can contain multiple documents. The reader handles this by adding an element as a child of the root element. An XML serialized YAML stream with one empty YAML document looks like this:
<yaml>
<document>
</document>
</yaml>The XML element name of the root element, the element name of the document, and the element name of array elements can be configured with the following configuration options:
-
rootName: The name of the root element. Default:yaml. -
documentName: The name of the document element. Default:document. -
elementName: The name of a sequence element. Default:element.
YAML allows characters in the key name that aren’t allowed in XML element name. To workaround that problem the reader offers multiple solutions. The YAML reader can search and replace white spaces, illegal characters and the number in key names that start with a number. It is also possible to replace one key name with a completely different name. The following example demonstrates all these features:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:yaml="https://www.smooks.org/xsd/smooks/yaml-1.5.xsd">
<yaml:reader keyWhitspaceReplacement="_" keyPrefixOnNumeric="n" illegalElementNameCharReplacement=".">
<yaml:keyMap>
<yaml:key from="some key">someKey</yaml:key>
<yaml:key from="some&key" to="someAndKey" />
</yaml:keyMap>
</yaml:reader>
</smooks-resource-list>-
keyWhitspaceReplacement: The replacement character for whitespaces in a yaml map key. By default this not defined, so that the reader doesn’t search for white spaces. -
keyPrefixOnNumeric: The prefix character to add if the YAML node name starts with a number. By default this is not defined, so that the reader doesn’t search for element names that start with a number. -
illegalElementNameCharReplacement: If illegal characters are encountered in a YAML element name then they are replaced with this value. By default this is not defined, so that the reader doesn’t search for element names with illegal characters.
YAML has the concept of anchors and aliases. The YAML reader can handle anchors and aliasses with three different strategies. The strategy is defined via the aliasStrategy configuration option. This option can have the following values:
-
REFER: The reader creates reference attributes on the element that have an anchor or an alias. The element with the anchor gets theidattribute containing the name from the anchor as the attribute value. The element with the alias gets therefattribute also containing the name of the anchor as the attribute value. The anchor and alias attribute names can be defined by theanchorAttributeNameandaliasAttributeName. -
RESOLVE: The reader resolves the value or the data structure of an anchor when its alias is encountered. This means that the SAX events of the anchor are repeated as child events of the alias element. When a YAML document contains a lot of anchors or anchors with a huge data structure then this can lead to memory problems. -
REFER_RESOLVE: This is a combination ofREFERandRESOLVE. The anchor and alias attributes are set but the anchor value or data structure is also resolved. This option is useful when the name of the anchor has a business meaning.
By the default the YAML reader uses the REFER strategy.
Java API
Smooks is programmatically configured to read a YAML configuration using the YamlReaderConfigurator class.
Smooks smooks = new Smooks();
smooks.setReaderConfig(new YamlReaderConfigurator()
.setRootName("root")
.setDocumentName("doc")
.setArrayElementName("e"))
.setAliasStrategy(AliasStrategy.REFER_RESOLVE)
.setAnchorAttributeName("anchor")
.setAliasAttributeName("alias");
// Use Smooks as normal...Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-yaml-cartridge</artifactId>
<version>2.0.3</version>
</dependency>XML Namespace
xmlns:yaml="https://www.smooks.org/xsd/smooks/yaml-1.5.xsd"
Validating Data
Rules
Rules in Smooks refer to a general concept and is not specific to any cartridge. A RuleProvider can be configured and referenced from other components. As of Smooks v1.2, the only Cartridge using Rules functionality is the Validation Cartridge.
So, lets start by looking at what rules in Smooks are, and how they are used.
Rule Configuration
Rules are centrally defined through ruleBase definitions. A single Smooks config can reference many ruleBase definitions. A rulesBase configuration consists of a name, a rule src, and a rule provider. The format of the rule source is entirely dependent on the provider implementation. The only requirement is that the individual rules be named (unique within the context of a single source) so as they can be referenced by their name.
An example of a ruleBase configuration is as follows:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:rules="https://www.smooks.org/xsd/smooks/rules-1.1.xsd">
<rules:ruleBases>
<rules:ruleBase name="regexAddressing" src="/org/smooks/validation/address.properties"
provider="org.smooks.rules.regex.RegexProvider" />
<rules:ruleBase name="order" src="/org/smooks/validation/order/rules/order-rules.csv"
provider="org.smooks.rules.mvel.MVELProvider"/>
</rules:ruleBases>
</smooks-resource-list>Rule Base Configuration Options
The following are the configuration options for the configuration element.
-
name: Is used to reference this rule from other components, like from a validation configuration that we will look at shortly. Required. -
src: Is a file or anything meaningful to the RuleProvider. This could be a file containing rules for example. Required. -
provider: Is the actual provider implementation that you want to use. This is where the different technologies come into play. In the above configuration we have one RuleProvider that uses regular expression. As you might have guessed you can specify multiple ruleBase element and have as many RuleProviders you need. Required.
RuleProvider Implementations
Rule Providers implement the org.smooks.rules.RuleProvider interface.
Smooks v1.2 supports 2 RuleProvider implementations out-of-the-box:
You can easily create custom RuleProvider implementations. Future versions of Smooks will probably include support for e.g. a Drools RuleProvider.
RegexProvider
As it’s name suggests, the RegexProvider is based on regular expression.It allows you to define low level rules specific to the format of specific fields of data in the message being filtered e.g. that a particular field is a valid email address.
Configuration of a Regex ruleBase would look like this:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:rules="https://www.smooks.org/xsd/smooks/rules-1.1.xsd">
<rules:ruleBases>
<rules:ruleBase name="customer" src="/org/smooks/validation/order/rules/customer.properties"
provider="org.smooks.rules.regex.RegexProvider"/>
</rules:ruleBases>
</smooks-resource-list>Regex expressions are defined in standard .properties file format. An example of a customer.properties Regex rule definition file (from the above example) might be as follows:
customer.properties
# Customer data rules...
customerId=[A-Z][0-9]{5}
customerName=[A-Z][a-z]*, [A-Z][a-z]The following is a list of "useful" regular expressions that we hope to grow over time as a resource for people use Regex Rules.
See the Regular Expression Library.
# Email Address Validation
email=^((?>[a-zA-Z\d!#$%&'*+\-/=?^_`{|}~]+\x20*|"((?=[\x01-\x7f])[^"\\]|\\[\x01-\x7f])*"\x20*)*(?<angle><))?((?!\.)(?>\.?[a-zA-Z\d!#$%&'*+\-/=?^_`{|}~]+)+|"((?=[\x01-\x7f])[^"\\]|\\[\x01-\x7f])*")@(((?!-)[a-zA-Z\d\-]+(?<!-)\.)+[a-zA-Z]{2,}|\[(((?(?<!\[)\.)(25[0-5]|2[0-4]\d|[01]?\d?\d)){4}|[a-zA-Z\d\-]*[a-zA-Z\d]:((?=[\x01-\x7f])[^\\\[\]]|\\[\x01-\x7f])+)\])(?(angle)>)$
# Matches a negative or positive percentage between 0 and 100 (inclusive). Accepts up to 2 decimal places.
percentage.withdecimal=^-?[0-9]{0,2}(\.[0-9]{1,2})?$|^-?(100)(\.[0]{1,2})?$
# HTTP/HTTPS Url
url.http=^(http|https)\://[a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,3}(:[a-zA-Z0-9]*)?/?([a-zA-Z0-9\-\._\?\,\'/\\\+&%\$#\=~])*$MVELProvider
The MVEL Provider allows rules to be defined as MVEL expressions. These expressions are executed on the contents of the Smooks Javabean bean context. That means they require Data to be bound (from the message being filtered) into Java objects in the Smooks bean context. This allows you to define more complex (higher level) rules on message fragments, such as "is the product in the targeted order item fragment within the age eligibility constraints of the customer specified in the order header details".
| Be sure to read the section on Java Binding. |
Configuration of an MVEL ruleBase would look like this:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:rules="https://www.smooks.org/xsd/smooks/rules-1.1.xsd">
<rules:ruleBases>
<rules:ruleBase name="order" src="/org/smooks/validation/order/rules/order-rules.csv" provider="org.smooks.rules.mvel.MVELProvider"/>
</rules:ruleBases>
</smooks-resource-list>MVEL rules must be defined as Comma Separated Value (CSV) files. The easiest way to edit these files is through a Spreadsheet Application (e.g. OpenOffice or Excel). Each rule record contains 2 fields:
-
A Rule Name
-
An MVEL Expression
Comment/header rows can be added by prefixing the first field with a hash ('#') character.
An example of an MVEL rule CSV file as seen in OpenOffice is as follows:
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-rules-cartridge</artifactId>
<version>2.0.3</version>
</dependency>XML Namespace
xmlns:rules="https://www.smooks.org/xsd/smooks/rules-1.1.xsd
Rule-Based Validation
The Smooks Validation Cartridge builds on the functionality provided by the rules cartridge, to provide rules-based fragment validation.
The type of validation provided by the components of the Smooks Validation Cartridge allows you to perform more detailed validation (over the likes of XSD/Relax) on message fragments. As with everything in Smooks, the Validation functionality is supported across all supported data formats. This means you can perform strong validation on not just XML data, but also on EDI, JSON, CSV, etc…
Validation configurations are defined by the https://www.smooks.org/xsd/smooks/validation-1.1.xsd configuration namespace.
Validation Configuration
Smooks supports a number of different Rule Provider types that can be used by the Validation Cartridge. They provide different levels of validation. These different forms of Validation are configured in exactly the same way. The Smooks Validation Cartridge sees a Rule Provider as an abstract resource that it can target at message fragments in order to perform validation on the data in that message fragment.
A Validation rule configuration is very simple. You simply need to specify:
-
executeOn: The fragment on which the rule is to be executed. -
excecuteOnNS: The fragment namespace (NS) that that 'executeOn' belongs to. -
name: The name of the rule to be applied. This is a Composite Rule Name that references aruleBaseandruleNamecombination in a dot delimited format i.e., ruleBaseName.ruleName. -
onFail: The severity of a failed match for the Validation rule. See onFail section for details.
An example of a validation rule configuration would be:
smooks-config.xml
<validation:rule executeOn="order/header/email" name="regexAddressing.email" onFail="ERROR" />Configuring Max Failures
One can set a maximum number of validation failures per Smooks filter operation. An exception will be thrown if this max value is exceeded.Note that validations configured with onFail="FATAL" will always throw an exception and stop processing.
To configure the maximum validation failures add this following to you Smooks configuration:
smooks-config.xml
<params>
<param name="validation.maxFails">5</param>
</params>onFail
The onFail attribute in the validation configuration specified what action should be taken when a rule matches. This is all about reporting back validation failures.
The following options are available:
-
OK: Save the validation as an ok validation. CallingValidationSink.getOkswill return all validation warnings. This can be useful for content based routing. -
WARN: Save the validation as a warning. CallingValidationSink.getWarningswill return all validation warnings. -
ERROR: Save the validation as an error. CallingValidationSink.getErrorswill return all validation errors. -
FATAL: Will throw aValidationExceptionas soon as a validation failure occurs. CallingValidationSink.getFatalwill return the fatal validation failure.
Composite Rule Name
When a RuleBase is referenced in Smooks you use a composite rule name in the following format:
<ruleProviderName>.<ruleName>ruleProviderName Identifies the rule provider and maps to the 'name' attribute in the 'ruleBase' element.
ruleName Identifies a specific rule the rule provider knows about.This could be a rule defined in the 'src' file/resource.
Validation Results
Validation results are captured by the Smooks.filterSource by specifying a ValidationSink instance in the filterSource method call. When the filterSource method returns, the ValidationSink instance will contain all validation data.
An example of executing Smooks in order to perform message fragment validation is as follows:
ValidationSink validationSink = new ValidationSink();
smooks.filterSource(new StreamSource(messageInStream), new StreamSink(messageOutStream), validationSink);
List<OnFailResult> errors = validationSink.getErrors();
List<OnFailResult> warnings = validationSink.getWarnings();As you can see from the above code, individual warning, error, and other validation results are made available from the ValidationSink object in the form of OnFailResult instances. The OnFailResult object provides details about an individual failure.
Localized Validation Messages
The Validation Cartridge provides support for specifying localized messages relating to Validation failures. These messages can be defined in standard Java ResourceBundle files (.properties format). A convention is used here, based on the rule source name (src). The validation message bundle base name is derived from the rule source by dropping the rule source file extension and adding an extra folder named i18n e.g. for an MVEL ruleBase source of /org/smooks/validation/order/rules/order-rules.csv, the corresponding validation message bundle base name would be "/org/smooks/validation/order/rules/i18n/order-rules".
The validation cartridge supports application of FreeMarker templates on the localized messages, allowing the messages to contain contextual data from the bean context, as well as data about the actual rule failure. FreeMarker based messages must be prefixed with ftl: and the contextual data is references using the normal FreeMarker notation. The beans from the bean context can be referenced directly, while the RuleEvalResult and rule failure path can be referenced through the ruleResult and path beans.
Example message using RegexProvider rules:
customerId=ftl:Invalid customer number '${ruleResult.text}' at '${path}'. Customer number must match pattern '${ruleResult.pattern}'.
Example
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-validation-cartridge</artifactId>
<version>2.0.3</version>
</dependency>Database Support
Smooks support for databases include:
-
JDBC resources to read from and write to the database using SQL.
-
Entity persistence resources to leverage persistence frameworks such as MyBatis, Hibernate, or any JPA compatible framework.
-
Data Access Object (DAO) resources where CRUD methods are invoked to issue database reads and writes.
JDBC
Consider an ETL scenario where order and order items needs to be saved to the database:
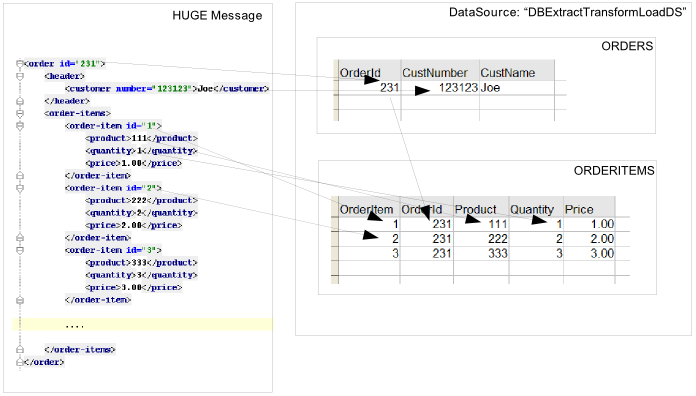
To route an order and order item data to a database, you should define a set of Java bindings that extract the order and order-item data from the input source stream:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<!-- Extract the order data... -->
<jb:bean beanId="order" class="java.util.Hashtable" createOnElement="order">
<jb:value property="orderId" decoder="Integer" data="order/@id"/>
<jb:value property="customerNumber" decoder="Long" data="header/customer/@number"/>
<jb:value property="customerName" data="header/customer"/>
</jb:bean>
<!-- Extract the order-item data... -->
<jb:bean beanId="orderItem" class="java.util.Hashtable" createOnElement="order-item">
<jb:value property="itemId" decoder="Integer" data="order-item/@id"/>
<jb:value property="productId" decoder="Long" data="order-item/product"/>
<jb:value property="quantity" decoder="Integer" data="order-item/quantity"/>
<jb:value property="price" decoder="Double" data="order-item/price"/>
</jb:bean>
</smooks-resource-list>Next you need to define datasource configuration, and a number of jdbc:executor configurations that will reference the datasource to insert the POJO fields into the database. This is the datasource configuration (namespace https://www.smooks.org/xsd/smooks/datasource-1.4.xsd) for retrieving a direct database connection:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:ds="https://www.smooks.org/xsd/smooks/datasource-1.4.xsd">
<ds:direct bindOnElement="#document"
datasource="DBExtractTransformLoadDS"
driver="org.hsqldb.jdbcDriver"
url="jdbc:hsqldb:hsql://localhost:9201/smooks-hsql-9201"
username="sa"
password=""
autoCommit="false"/>
</smooks-resource-list>It is also possible to use a JNDI datasource for retrieving a database connection:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:ds="https://www.smooks.org/xsd/smooks/datasource-1.4.xsd">
<!-- This JNDI datasource can handle JDBC and JTA transactions or
it can leave the transaction managment to an other external component.
An external component could be an other Smooks visitor, the EJB transaction manager
or you can do it your self. -->
<ds:JNDI
bindOnElement="#document"
datasource="DBExtractTransformLoadDS"
datasourceJndi="java:/someDS"
transactionManager="JTA"
transactionJndi="java:/mockTransaction"
targetProfile="jta"/>
</smooks-resource-list>The datasource schema describes and documents how you can configure the datasource. This is the jdbc:executor configuration (namespace https://www.smooks.org/xsd/smooks/jdbc-2.0.xsd):
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jdbc="https://www.smooks.org/xsd/smooks/jdbc-2.0.xsd">
<!-- Assert whether it's an insert or update. Need to do this just before we do the insert/update... -->
<jdbc:executor executeOnElement="order-items" datasource="DBExtractTransformLoadDS" executeBefore="true">
<jdbc:statement>select OrderId from ORDERS where OrderId = ${order.orderId}</jdbc:statement>
<jdbc:resultSet name="orderExistsRS"/>
</jdbc:executor>
<!-- If it's an insert (orderExistsRS.isEmpty()), insert the order before we process the order items... -->
<jdbc:executor executeOnElement="order-items" datasource="DBExtractTransformLoadDS" executeBefore="true">
<condition>orderExistsRS.isEmpty()</condition>
<jdbc:statement>INSERT INTO ORDERS VALUES(${order.orderId}, ${order.customerNumber}, ${order.customerName})</jdbc:statement>
</jdbc:executor>
<!-- And insert each orderItem... -->
<jdbc:executor executeOnElement="order-item" datasource="DBExtractTransformLoadDS" executeBefore="false">
<condition>orderExistsRS.isEmpty()</condition>
<jdbc:statement>INSERT INTO ORDERITEMS VALUES (${orderItem.itemId}, ${order.orderId}, ${orderItem.productId}, ${orderItem.quantity}, ${orderItem.price})</jdbc:statement>
</jdbc:executor>
<!-- Ignoring updates for now!! -->
</smooks-resource-list>A functional version of this example is available online.
Persistence
You can directly use several persistence frameworks from within Smooks (Hibernate, JPA, etc…).
Let us take a look at a Hibernate example. The same principals follow for any JPA compliant framework.
The data we are going to process is an XML order message. It should be noted however, that the input data could also be CSV, JSON, EDI, Java or any other structured data format. The same principals apply, no matter what the data format is!
<order>
<ordernumber>1</ordernumber>
<customer>123456</customer>
<order-items>
<order-item>
<product>11</product>
<quantity>2</quantity>
</order-item>
<order-item>
<product>22</product>
<quantity>7</quantity>
</order-item>
</order-items>
</order>The Hibernate entities are:
@Entity
@Table(name="orders")
public class Order {
@Id
private Integer ordernumber;
@Basic
private String customerId;
@OneToMany(mappedBy = "order", cascade = CascadeType.ALL)
private List orderItems = new ArrayList();
public void addOrderLine(OrderLine orderLine) {
orderItems.add(orderLine);
}
// Getters and Setters....
}
@Entity
@Table(name="orderlines")
public class OrderLine {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
@ManyToOne
@JoinColumn(name="orderid")
private Order order;
@Basic
private Integer quantity;
@ManyToOne
@JoinColumn(name="productid")
private Product product;
// Getters and Setters....
}
@Entity
@Table(name = "products")
@NamedQuery(name="product.byId", query="from Product p where p.id = :id")
public class Product {
@Id
private Integer id;
@Basic
private String name;
// Getters and Setters....
}What we want to do here is to process and persist the Order. First thing we need to do is to bind the order data into the Order entities (Order, OrderLine and Product). To do this we need to:
-
Create and populate the Order and OrderLine entities using the Java Binding framework.
-
Wire each OrderLine instance into the Order instance.
-
Into each OrderLine instance, we need to lookup and wire in the associated order line Product entity.
-
And finally, we need to insert (persist) the Order instance.
To do this, we need the following Smooks configuration:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd"
xmlns:persistence="https://www.smooks.org/xsd/smooks/persistence-2.0.xsd">
<jb:bean beanId="order" class="example.entity.Order" createOnElement="order">
<jb:value property="ordernumber" data="ordernumber" />
<jb:value property="customerId" data="customer" />
<jb:wiring setterMethod="addOrderLine" beanIdRef="orderLine" />
</jb:bean>
<jb:bean beanId="orderLine" class="example.entity.OrderLine" createOnElement="order-item">
<jb:value property="quantity" data="quantity" />
<jb:wiring property="order" beanIdRef="order" />
<jb:wiring property="product" beanIdRef="product" />
</jb:bean>
<persistence:locator beanId="product" lookupOnElement="order-item" onNoResult="EXCEPTION" uniqueResult="true">
<persistence:query>from Product p where p.id = :id</persistence:query>
<persistence:params>
<persistence:value name="id" data="product" decoder="Integer" />
</persistence:params>
</persistence:locator>
<persistence:inserter beanId="order" insertOnElement="order" />
</smooks-resource-list>If we want to use the named query productById instead of the query string then the DAO locator configuration will look like this:
<persistence:locator beanId="product" lookupOnElement="order-item" lookup="product.byId" onNoResult="EXCEPTION" uniqueResult="true">
<persistence:params>
<persistence:value name="id" data="product" decoder="Integer"/>
</persistence:params>
</persistence:locator>The following code executes Smooks. Note that we use a SessionRegister object so that we can access the Hibernate Session from within Smooks.
Smooks smooks = new Smooks("smooks-config.xml");
ExecutionContext executionContext = smooks.createExecutionContext();
// The SessionRegister provides the bridge between Hibernate and the
// Persistence Cartridge. We provide it with the Hibernate session.
// The Hibernate Session is set as default Session.
DaoRegister register = new SessionRegister(session);
// This sets the DAO Register in the executionContext for Smooks
// to access it.
PersistenceUtil.setDAORegister(executionContext, register);
Transaction transaction = session.beginTransaction();
smooks.filterSource(executionContext, source);
transaction.commit();Data Access Objects
Now let’s take a look at a DAO based example. The example will read an XML file containing order information (note that this works just the same for EDI, CSV, etc…). Using the javabean cartridge, it will bind the XML data into a set of entity beans. Using the id of the products within the order items (the element) it will locate the product entities and bind them to the order entity bean. Finally, the order bean will be persisted.
The order XML message looks like this:
<order>
<ordernumber>1</ordernumber>
<customer>123456</customer>
<order-items>
<order-item>
<product>11</product>
<quantity>2</quantity>
</order-item>
<order-item>
<product>22</product>
<quantity>7</quantity>
</order-item>
</order-items>
</order>The following custom DAO will be used to persist the Order entity:
@Dao
public class OrderDao {
private final EntityManager em;
public OrderDao(EntityManager em) {
this.em = em;
}
@Insert
public void insertOrder(Order order) {
em.persist(order);
}
}When looking at this class you should notice the @Dao and @Insert annotations. The @Dao annotation declares that the OrderDao is a DAO object. The @Insert annotation declares that the insertOrder method should be used to insert Order entities.
The following custom DAO will be used to lookup the Product entities:
@Dao
public class ProductDao {
private final EntityManager em;
public ProductDao(EntityManager em) {
this.em = em;
}
@Lookup(name = "id")
public Product findProductById(@Param("id")int id) {
return em.find(Product.class, id);
}
}When looking at this class, you should notice the @Lookup and @Param annotations. The @Lookup annotation declares that the ProductDao#findByProductId method is used to lookup Product entities. The name parameter in the @Lookup annotation sets the lookup name reference for that method. When the name isn’t declared, the method name will be used. The optional @Param annotation lets you name the parameters. This creates a better abstraction between Smooks and the DAO. If you don’t declare the @Param annotation the parameters are resolved by there position.
The Smooks configuration look likes this:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd"
xmlns:persistence="https://www.smooks.org/xsd/smooks/persistence-2.0.xsd">
<jb:bean beanId="order" class="example.entity.Order" createOnElement="order">
<jb:value property="ordernumber" data="ordernumber"/>
<jb:value property="customerId" data="customer"/>
<jb:wiring setterMethod="addOrderLine" beanIdRef="orderLine"/>
</jb:bean>
<jb:bean beanId="orderLine" class="example.entity.OrderLine" createOnElement="order-item">
<jb:value property="quantity" data="quantity"/>
<jb:wiring property="order" beanIdRef="order"/>
<jb:wiring property="product" beanIdRef="product"/>
</jb:bean>
<persistence:locator beanId="product" dao="product" lookup="id" lookupOnElement="order-item" onNoResult="EXCEPTION">
<persistence:params>
<persistence:value name="id" data="product" decoder="Integer"/>
</persistence:params>
</persistence:locator>
<persistence:inserter beanId="order" dao="order" insertOnElement="order"/>
</smooks-resource-list>The following code executes Smooks:
Smooks smooks=new Smooks("./smooks-configs/smooks-dao-config.xml");
ExecutionContext executionContext=smooks.createExecutionContext();
// The register is used to map the DAO's to a DAO name. The DAO name isbe used in
// the configuration.
// The MapRegister is a simple Map like implementation of the DaoRegister.
DaoRegister<object>register = MapRegister.builder()
.put("product",new ProductDao(em))
.put("order",new OrderDao(em))
.build();
PersistenceUtil.setDAORegister(executionContext,mapRegister);
// Transaction management from within Smooks isn't supported yet,
// so we need to do it outside the filter execution
EntityTransaction tx=em.getTransaction();
tx.begin();
smooks.filter(new StreamSource(messageIn),null,executionContext);
tx.commit();Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges.persistence</groupId>
<artifactId>smooks-persistence-cartridge</artifactId>
<version>2.0.3</version>
</dependency>XML Namespaces
xmlns:ds="https://www.smooks.org/xsd/smooks/datasource-1.4.xsd"
xmlns:jdbc="https://www.smooks.org/xsd/smooks/jdbc-2.0.xsd"
xmlns:persistence="https://www.smooks.org/xsd/smooks/persistence-2.0.xsd"
Scripting
Groovy
Support for Groovy scripting is made available through the https://www.smooks.org/xsd/smooks/groovy-2.0.xsd configuration namespace.
Example configuration:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:g="https://www.smooks.org/xsd/smooks/groovy-2.0.xsd">
<g:groovy executeOnElement="xxx">
<g:script>
<!--
//Rename the target fragment element from "xxx" to "yyy"...
DomUtils.renameElement(element, "yyy", true, true);
-->
</g:script>
</g:groovy>
</smooks-resource-list>Usage Tips
-
Imports can be added via the
importselement. A number of classes are automatically imported:-
org.smooks.support.DomUtils -
org.smooks.api.bean.context.BeanContext -
org.smooks.api.bean.repository.BeanRepository -
org.w3c.dom.* -
groovy.xml.dom.DOMCategory,groovy.xml.dom.DOMUtil,groovy.xml.DOMBuilder
-
-
The visited element is available to the script through the variable
element. It is also available under a variable name equal to the element name, but only if the element name contains alpha-numeric characters only. -
By default, the script is executed on the visitAfter event. You can direct it to be executed on the visitBefore by setting the
executeBeforeattribute totrue. -
If the script contains special XML characters, it can be wrapped in an XML Comment or CDATA section.
Groovy Scriptlet Variables and Methods
A number of variables and methods are made directly available to groovy scriptlet code i.e. you can reference them directly in your scriptlet.
Variables
-
element: The DOM/SAX Element (depending on which filter type is in use) i.e.org.w3c.dom.Elementororg.api.smooks.delivery.sax.SAXElement. -
executionContext: The SmooksExecutionContextinstance associated with the Smooks filtering operation. -
nodeModels: A map containing all the DOM NodeModels currently available (i.e.,Map<String, Element>).
Methods
-
Get a bean from
Object BeanContext#getBean(String beandId).
Adding Beans to the BeanContext
As shown above, all scriptlet code can access the beans by calling BeanContext#getBean(String) from inside the scriptlet code. One oversight when implementing this feature was that we didn’t provide an addBean method for adding beans to the bean context. However, it is still possible to do so in a slightly more long-winded method via the executionContext e.g.:
executionContext.getBeanContext().addBean("myBean", myBeanInstance);Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-scripting-cartridge</artifactId>
<version>2.0.3</version>
</dependency>Routing
A common approach to processing large/huge messages is to split them out into smaller messages that can be processed independently. Of course splitting and routing is not just a solution for processing huge messages. It’s often needed with smaller messages as well (message size may be irrelevant) where, for example, order items in an order message need to be split out and routed (based on content - "Content Base Routing") to different departments or partners for processing. Under these conditions, the message formats required at the different destinations may also vary e.g.,
-
"destination1" required XML via the file system,
-
"destination2" requires Java objects via a JMS Queue,
-
"destination3" picks the messages up from a table in a database, etc…
-
"destination4" requires EDI messages via a JMS Queue,
-
etc etc
With Smooks, all of the above is possible. You can perform multiple splitting and routing operations to multiple destinations (of different types) in a single pass over a message.
The basic concept is simple. As you stream the message through Smooks:
-
Repeatedly create a standalone message (split) for the fragment to be routed.
-
Repeatedly bind the split message into the bean context under a unique beanId.
-
Repeatedly route the split message to the required endpoint (File, DB, JMS, ESB).
We emphasize "Repeatedly" (above) so as to reinforce the point that these operations happen for each instance of the split message found in the source message e.g. for each in an message.
As for points #1 and #2 above specifically, Smooks offers two approaches to creating the split messages:
-
A basic (untransformed/unenriched) fragment split and bind. This is a very simple configuration that simply serializes a message fragment (repeatedly) to its XML form and stores it in the bean context as a String.
-
A more complex approach using the Java Binding and Templating Cartridges, where you configure Smooks to extract data from the source message and into the bean context (using configs) and then (optionally) apply templates to create the split messages. This is more complex, but offers the following advantages:
-
Allows for transformation of the split fragments i.e. not just XML as with the basic option.
-
Allows for enrichment of the message.
-
Allows for more complex splits, with the ability to merge data from multiple source fragments into each split message e.g. not just the fragments, but the order info too.
-
Allows for splitting and routing of Java Objects as the Split messages (e.g., over JMS).
-
With the more complex approach outlined above, the key to processing huge messages (not an issue for the more basic approach) is to make sure that you always maintain a small memory footprint. You can do this using the JavaBean Cartridge by making sure you’re only binding the most relevant message data (into the bean context) at any one time. In the following sections, the examples are all based on splitting and routing of order-items out of an order message. The solutions shown all work for huge messages because the Smooks JavaBean Cartridge binding configurations are implemented such that the only data held in memory at any given time is the main order details (order header etc…), and the "current" order item details.
Basic Splitting and Routing
As stated above, the easiest way to split and route fragments of a message is to use the basic <frag:serialize> and <*:router> components (<jms:router>, <file:router>, etc…) from the Routing Cartridge. The <frag:serialize> component has its own configuration in the https://www.smooks.org/xsd/smooks/fragment-routing-1.5.xsd namespace.
The following is an example for serializing the contents of a SOAP message body and storing it in the Bean Context under the beanId of soapBody:
smooks-config
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:frag="https://www.smooks.org/xsd/smooks/fragment-routing-1.5.xsd">
<frag:serialize fragment="Envelope/Body" bindTo="soapBody" childContentOnly="true"/>
</smooks-resource-list>Then the Smooks code for executing this:
Smooks smooks = new Smooks(configStream);
JavaSink javaSink = new JavaSink();
smooks.filterSource(new StreamSource(soapMessageStream), javaSink);
String bodyContent = javaSink.getBean("soapBody").toString().trim();And of course, you can do all of this programmatically too (i.e., no need for the XML config):
Smooks smooks = new Smooks();
smooks.addVisitor(new FragmentSerializer().setBindTo("soapBody"), "Envelope/Body");
JavaSink javaSink = new JavaSink();
smooks.filterSource(new StreamSource(soapMessageStream), javaSink);
String bodyContent = javaSink.getBean("soapBody").toString().trim();The code snippets above only show how to create the split messages and bind them into the bean context, from where they can be accessed. How about routing these split messages to another endpoint for processing?Well it’s easy, just use one of the routing components as outlined in the following sections.
The following is a quick example, showing the config for routing split messages (this time fragments) to a JMS Destination for processing:
smooks-config
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:frag="https://www.smooks.org/xsd/smooks/fragment-routing-1.5.xsd" xmlns:jms="https://www.smooks.org/xsd/smooks/jms-routing-2.0.xsd">
<!-- Create the split messages for the order items... -->
<frag:serialize fragment="order-items/order-item" bindTo="orderItem" />
<!-- Route each order items split mesage to the orderItem JMS processing queue... -->
<jms:router routeOnElement="order-items/order-item" beanId="orderItem" destination="orderItemProcessingQueue" />
</smooks-resource-list>For more details on the JMS routing aspects of the above example, see the JMS Router documentation (below). The <jms:router> could be substituted for any of the other routers e.g. if using with JBoss ESB, you could use the <esbr:routeBean> configuration to route the split message to any ESB endpoint.
File
File based routing is performed via the <file:outputStream> configuration from the
https://www.smooks.org/xsd/smooks/file-routing-2.0.xsd configuration namespace.
This section illustrates how you can combine the following Smooks functionality to split a message out into smaller messages on the file system.
-
The Javabean cartridge for extracting data from the message and holding it in variables in the bean context. In this case, we could also use DOM NodeModels for capturing the order and order-item data to be used as the templating data models.
-
The
<file:outputStream>configuration from the routing cartridge for managing file system streams (naming, opening, closing, throttling creation, etc…). -
The templating cartridge (FreeMarker Templates) for generating the individual split messages from data bound in the bean context by the JavaBean cartridge (see #1 above). The templating result is written to the file output stream (#2 above).
In the example, we want to process a huge order message and route the individual order item details to file. The following illustrates what we want to achieve. As you can see, the split messages don’t just contain data from the order item fragments. They also contain data from the order header and root elements.
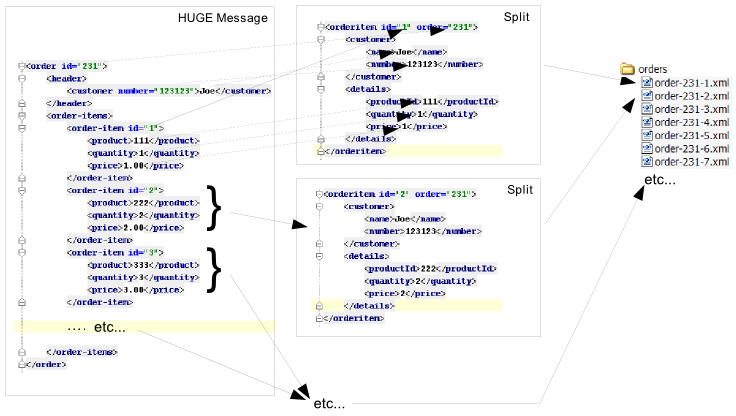
To achieve this with Smooks, we assemble the following Smooks configuration:
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd"
xmlns:file="https://www.smooks.org/xsd/smooks/file-routing-2.0.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.0.xsd">
<!-- Extract and decode data from the message. Used in the freemarker template (below).
Note that we could also use a NodeModel here... -->
(1) <jb:bean beanId="order" class="java.util.Hashtable" createOnElement="order">
<jb:value property="orderId" decoder="Integer" data="order/@id"/>
<jb:value property="customerNumber" decoder="Long" data="header/customer/@number"/>
<jb:value property="customerName" data="header/customer"/>
<jb:wiring property="orderItem" beanIdRef="orderItem"/>
</jb:bean>
(2) <jb:bean beanId="orderItem" class="java.util.Hashtable" createOnElement="order-item">
<jb:value property="itemId" decoder="Integer" data="order-item/@id"/>
<jb:value property="productId" decoder="Long" data="order-item/product"/>
<jb:value property="quantity" decoder="Integer" data="order-item/quantity"/>
<jb:value property="price" decoder="Double" data="order-item/price"/>
</jb:bean>
<!-- Create/open a file output stream. This is writen to by the freemarker template (below).. -->
(3) <file:outputStream openOnElement="order-item" resourceName="orderItemSplitStream">
<file:fileNamePattern>order-${order.orderId}-${order.orderItem.itemId}.xml</file:fileNamePattern>
<file:destinationDirectoryPattern>target/orders</file:destinationDirectoryPattern>
<file:listFileNamePattern>order-${order.orderId}.lst</file:listFileNamePattern>
<file:highWaterMark mark="10"/>
</file:outputStream>
<!--
Every time we hit the end of an <order-item> element, apply this freemarker template,
outputting the result to the "orderItemSplitStream" OutputStream, which is the file
output stream configured below.
-->
(4) <core:smooks filterSourceOn="order-item">
<core:action>
<!-- Output the templating result to the "orderItemSplitStream" file output stream... -->
<core:outputTo outputStreamResource="orderItemSplitStream"/>
</core:action>
<core:config>
<smooks-resource-list>
<ftl:freemarker applyOnElement="order-item">
<ftl:template>target/classes/orderitem-split.ftl</ftl:template>
</ftl:freemarker>
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>Smooks Resource configuration #1 and #2 define the Java Bindings for extracting the order header information (config #1) and the order-item information (config #2). This is the key to processing a huge message; making sure that we only have the current order item in memory at any one time. The Smooks Javabean Cartridge manages all this for you, creating and recreating the orderItem beans as the fragments are being processed.
The <file:outputStream> configuration in configuration #3 manages the generation of the files on the file system. As you can see from the configuration, the file names can be dynamically constructed from data in the bean context. You can also see that it can throttle the creation of the files via the highWaterMark configuration parameter. This helps you manage file creation so as not to overwhelm the target file system.
Smooks Resource configuration #4 defines the FreeMarker templating resource used to write the split messages to the OutputStream created by the file:outputStream (config #3). See how config #4 references the file:outputStream resource. The Freemarker template is as follows:
<orderitem id="${.vars["order-item"].@id}" order="${order.@id}">
<customer>
<name>${order.header.customer}</name>
<number>${order.header.customer.@number}</number>
</customer>
<details>
<productId>${.vars["order-item"].product}</productId>
<quantity>${.vars["order-item"].quantity}</quantity>
<price>${.vars["order-item"].price}</price>
</details>
</orderitem>JMS
JMS routing is performed via the <jms:router> configuration from the https://www.smooks.org/xsd/smooks/jms-routing-2.0.xsd configuration namespace.
The following is an example <jms:router> configuration that routes an orderItem_xml bean to a JMS Queue named smooks.exampleQueue (also read the "Routing to File" example):
smooks-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:jms="https://www.smooks.org/xsd/smooks/jms-routing-2.0.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.0.xsd">
(1) <resource-config selector="order,order-item">
<resource>org.smooks.engine.resource.visitor.dom.DomModelCreator</resource>
</resource-config>
(2) <jms:router routeOnElement="order-item" beanId="orderItem_xml" destination="smooks.exampleQueue">
<jms:message>
<!-- Need to use special FreeMarker variable ".vars" -->
<jms:correlationIdPattern>${order.@id}-${.vars["order-item"].@id}</jms:correlationIdPattern>
</jms:message>
<jms:highWaterMark mark="3"/>
</jms:router>
(3) <core:smooks filterSourceOn="order-item">
<!-- Bind the templating result into the bean context, from where
it can be accessed by the JMSRouter (configured above). -->
<core:action>
<core:bindTo id="orderItem_xml"/>
</core:action>
<core:config>
<smooks-resource-list>
<!-- At each "order-item", apply a template to the "order" and "order-item" DOM model... -->
<ftl:freemarker applyOnElement="#document">
<!--
Note in the template that we need to use the special FreeMarker variable ".vars"
because of the hyphenated variable names ("order-item"). See http://freemarker.org/docs/ref_specvar.html.
-->
<ftl:template>/orderitem-split.ftl</ftl:template>
</ftl:freemarker>
</smooks-resource-list>
</core:config>
</core:smooks>
</smooks-resource-list>In this case, we route the result of a FreeMarker templating operation to the JMS Queue (i.e. as a String). We could also have routed a full Object Model, in which case it would be routed as a Serialized ObjectMessage.
Apache Camel
| The Camel cartridge is deprecated. It is superseded by the Camel Smooks Component and the Camel Smooks Data Format. |
It is possible to route fragments to Apache Camel endpoints using the <camel:route> configuration from the https://www.smooks.org/xsd/smooks/camel-1.5.xsd configuration namespace.
For example, you can route to Camel endpoint by specifying the following in your Smooks configuration:
smooks-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:camel="https://www.smooks.org/xsd/smooks/camel-1.5.xsd">
<!-- Create some bean instances from the input source... -->
<jb:bean beanId="orderItem" ...>
<!-- etc... See Smooks Java Binding docs -->
</jb:bean>
<!-- Route bean to camel endpoints... -->
<camel:route beanid="orderItem">
<camel:to endpoint="direct:slow" if="orderItem.priority == 'Normal'"/>
<camel:to endpoint="direct:express" if="orderItem.priority == 'High'"/>
</camel:route>
</smooks-resource-list>In the above example, we route Java Beans from Smooks’s BeanContext to the Camel Endpoints. Note that you can also apply templates (e.g., FreeMarker) to these same beans and route the templating result instead of beans (e.g., as XML, CSV or other).
The above configuration shows routing using the beanId attribute. It is also possible to route using an attribute named routeOnElement.
Apache Camel Integration
Integrating Smooks from Apache Camel lets you access all the features of Smooks from within Camel. You can take an existing Smooks configuration and use this in your Camel routes using one of the options that are described in this chapter.
Using Smooks in Camel can be done in three ways:
SmooksComponent
The SmooksComponent is a Camel Component which can used when you want to process the Camel Message Body using Smooks. You can do this by adding a route in your Camel route configuration:
from("file://inputDir?noop=true")
.to("smooks://smooks-config.xml")
.to("jms:queue:order")The Smooks Component is configured with a mandatory configuration file, which is smooks-config-xml in the example above. By just looking at the above route definition it is not clear what type of output that the SmooksComponent is producing. This is actually expressed in the Smooks configuration using the exports element.
If you prefer/require programmatic configuration of Smooks you can use the SmooksProcessor to achieve this.
An Apache Component can take options that are specified after the Smooks configuration file. Currently only one option is available for the SmooksComponent:
-
reportPathwhich is path (including the file name) to the Smooks Execution Report to be generated.
SmooksDataFormat
SmooksDataFormat is a Camel DataFormat which is capable of transforming from one data format to another and back again. You would use this when you are only interested in transforming from one format to another and not interested in other Smooks features.
Below is an example of using SmooksDataFormat to transform a comma separated value string into a java.util.List of Customer object instances:
SmooksDataFormat sdf = new SmooksDataFormat("csv-smooks-unmarshal-config.xml");
from("direct:unmarshal")
.unmarshal(sdf)
.convertBodyTo(List.class)
.to("mock:result");SmooksProcessor
Using SmooksProcessor gives you full control over Smooks, for example if you want to programmatically create the underlying Smooks instance you’d use SmooksProcessor. When using SmooksProcessor, you can pass a Smooks instance to its constructor and prior to that programmatically configure Smooks.
Below is an example of using the SmooksProcessor in a Camel route:
Smooks smooks = new Smooks("edi-to-xml-smooks-config.xml");
ExecutionContext context = smooks.createExecutionContext();
...
SmooksProcessor processor = new SmooksProcessor(smooks, context);
from("file://input?noop=true")
.process(processor)
.to("mock:result");Similar to the SmooksComponent we have not specified the result type that Smooks produces (if any that is). Instead this is expressed in the Smooks configuration using the exports element, or you can do the same programmatically like this:
Smooks smooks = new Smooks();
ExecutionContext context = smooks.createExecutionContext();
smooks.setExports(new Exports(StringResult.class));
SmooksProcessor processor = new SmooksProcessor(smooks, context);
...
from("file://input?noop=true")
.process(processor)
.to("mock:result");| See the Apache Camel examples in the examples page. |
Maven Coordinates
pom.xml
<dependency>
<groupId>org.smooks.cartridges</groupId>
<artifactId>smooks-camel-cartridge</artifactId>
<version>4.0.0</version>
</dependency>Exporting Results
When using Smooks standalone you are in full control of the type of output that Smooks produces since you specify it by passing a certain Sink to the filter method. But when integrating Smooks with other frameworks (JBossESB, Mule, Camel, and others) this needs to be specified inside the framework’s configuration. Starting with version 1.4 of Smooks you can now declare the data types that Smooks produces and you can use the Smooks api to retrieve the Sink(s) that Smooks exports.
To declare the type of sink that Smooks produces you use the 'exports' element as shown below:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd" xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd">
<core:exports>
<core:result type="org.smooks.io.sink.JavaSink"/>
</core:exports>
</smooks-resource-list>The newly added exports element declares the results that are produced by this Smooks configuration. A exports element can contain one or more result elements. A framework that uses Smooks could then perform filtering like this:
// Get the Exported types that were configured.
Exports exports = Exports.getExports(smooks.getApplicationContext());
if (exports.hasExports())
{
// Create the instances of the Sink types.
// (Only the types, i.e the Class type are declared in the 'type' attribute.
Sink[] sinks = exports.createSinks();
smooks.filterSource(executionContext, getSource(exchange), sinks);
// The Sink(s) will now be populate by Smooks filtering process and
// available to the framework in question.
}There might also be cases where you only want a portion of the result extracted and returned. You can use the ‘extract’ attribute to specify this:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd">
<core:exports>
<core:result type="org.smooks.io.sink.JavaSink" extract="orderBean"/>
</core:exports>
</smooks-resource-list>The extract attribute is intended to be used when you are only interested in a sub-section of a produced result. In the example above we are saying that we only want the object named orderBean to be exported. The other contents of the JavaSink will be ignored. Another example where you might want to use this kind of extracting could be when you only want a ValidationSink of a certain type, for example to only return validation errors.
Below is an example of using the extracts option from an embedded framework:
// Get the Exported types that were configured.
Exports exports = Exports.getExports(smooks.getApplicationContext());
if (exports.hasExports())
{
// Create the instances of the Sink types.
// (Only the types, i.e the Class type are declared in the 'type' attribute.
Sink[] sinks = exports.createSinks();
smooks.filterSource(executionContext, getSource(exchange), sinks);
List<object> objects = Exports.extractSinks(sinks, exports);
// Now make the object available to the framework that this code is running:
// Camel, JBossESB, Mule, etc...
}Performance Tuning
Like with any Software, when configured or used incorrectly, performance can be one of the first things to suffer. Smooks is no different in this regard.
General
-
Cache and reuse the Smooks Object. Initialization of Smooks takes some time and therefore it is important that it is reused.
-
Pool reader instances where possible. This can result in a huge performance boost, as some readers are very expensive to create.
-
If possible, use SAX NG filtering. However, you need to check that all Smooks cartridges in use are SAX NG compatible. SAX NG processing is faster than DOM processing and has a consistently small memory footprint. It is especially recommended for processing large messages. See the Filtering Process Selection (DOM or SAX?) section. SAX NG is the default filter since Smooks 2.
-
Turn off debug logging. Smooks performs some intensive debug logging in parts of the code. This can result in significant additional processing overhead and lower throughput. Also remember that NOT having your logging configured (at all) may result in debug log statements being executed!!
-
Contextual selectors can obviously have a negative effect on performance e.g. evaluating a match for a selector like "a/b/c/d/e" will obviously require more processing than that of a selector like "d/e". Obviously there will be situations where your data model will require deep selectors, but where it does not, you should try to optimize them for the sake of performance.
Smooks Cartridges
Every cartridge can have its own performance optimization tips.
Javabean Cartridge
-
If possible don’t use the Virtual Bean Model. Create Beans instead of maps. Creating and adding data to Maps is a lot slower then creating simple POJO’s and calling the setter methods.
Testing
Unit Testing
Unit testing with Smooks is simple:
public class MyMessageTransformTest {
@Test
public void test_transform() throws Exception {
Smooks smooks = new Smooks(getClass().getResourceAsStream("smooks-config.xml"));
try {
Source source = new StreamSource(getClass().getResourceAsStream("input-message.xml" ) );
StringSink sink = new StringSink();
smooks.filterSource(source, sink);
// compare the expected xml with the transformation result.
XMLUnit.setIgnoreWhitespace(true);
XMLAssert.assertXMLEqual(new InputStreamReader(getClass().getResourceAsStream("expected.xml")), new StringReader(sink.getResult()));
} finally {
smooks.close();
}
}
}The test case above uses XMLUnit.
The following maven dependency was used for xmlunit in the above test:
<dependency>
<groupId>xmlunit</groupId>
<artifactId>xmlunit</artifactId>
<version>1.1</version>
</dependency>Extending Smooks
All existing Smooks functionality (Java Binding, EDI processing, etc…) is built through extension of a number of well-defined APIs. We will look at these APIs in the coming sections.
The main extension points/APIs in Smooks are:
-
Reader APIs: Those for processing Source/Input data (Readers) so as to make it consumable by other Smooks components as a series of well defined hierarchical events (based on the SAX event model) for all of the message fragments and sub-fragments.
-
Visitor APIs: Those for consuming the message fragment SAX events produced by a source/input reader.
Another very important aspect of writing Smooks extensions is how these components are configured. Because this is common to all Smooks components, we will look at this first.
Configuring Smooks Components
All Smooks components are configured in exactly the same way. As far as the Smooks Core code is concerned, all Smooks components are "resources" and are configured via a ResourceConfig instance, which we talked about in earlier sections.
Smooks provides mechanisms for constructing namespace (XSD) specific XML configurations for components, but the most basic configuration (and the one that maps directly to the ResourceConfig class) is the basic XML configuration from the base configuration namespace (https://www.smooks.org/xsd/smooks-2.0.xsd).
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<resource-config selector="">
<resource></resource>
<param name=""></param>
</resource-config>
</smooks-resource-list>Where:
-
The
selectorattribute is the mechanism by which the resource is "selected" e.g. can be an XPath for a visitor. We’ll see more of this in the coming sections. -
The
resourceelement is the actual resource. This can be a Java Class name or some other form of resource (such as a template). For the purposes of this section however, lets just assume the resource to by a Java Class name. -
The
paramelements are configuration parameters for the resource defined in the resource element.
Smooks takes care of all the details of creating the runtime representation of the resource (e.g. constructing the class named in the resource element) and injecting all the configuration parameters. It also works out what the resource type is, and from that, how to interpret things like the selector e.g., if the resource is a visitor instance, it knows the selector is an XPath, selecting a Source message fragment.
Configuration Annotations
After your component has been created, you need to configure it with the element details. This is done using the @Inject annotation.
@Inject
The Inject annotation reflectively injects the named parameter (from the elements) having the same name as the annotated property itself (the name can actually be different, but by default, it matches against the name of the component property).
Suppose we have a component as follows:
public class DataSeeder {
@Inject
private File seedDataFile;
public File getSeedDataFile() {
return seedDataFile;
}
// etc...
}We configure this component in Smooks as follows:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<resource-config selector="dataSeeder">
<resource>com.acme.DataSeeder</resource>
<param name="seedDataFile">./seedData.xml</param>
</resource-config>
</smooks-resource-list>This annotation eliminates a lot of noisy code from your component because it:
-
Handles decoding of the value before setting it on the annotated component property. Smooks provides type converters for all the main types (Integer, Double, File, Enums, etc…), but you can implement and use a custom TypeConverter where the out-of-the-box converters don’t cover specific decoding requirements. Smooks will automatically use your custom converter if it is registered. See the TypeConverter Javadocs for details on registering a TypeConverter implementation such that Smooks will automatically locate it for converting a specific data type.
-
Supports enum constraints for the injected property, generating a configuration exception where the configured value is not one of the defined choice values. For example, you may have a property which has a constrained value set of "ON" and "OFF". You can use an enum for the property type to constrain the value, raise exceptions, etc…:
@Inject
private OnOffEnum foo;-
Can specify default property values:
@Inject
private Boolean foo = true;-
Can specify whether the property is optional:
@Inject
private java.util.Optional<Boolean> foo;By default, all properties are required but setting a default implicitly marks the property as being optional.
@PostConstruct and @PreDestroy
The Inject annotation is great for configuring your component with simple values, but sometimes your component needs more involved configuration for which we need to write some "initialization" code. For this, Smooks provides @PostConstruct.
On the other side of this, there are times when we need to undo work performed during initialization when the associated Smooks instance is being discarded (garbage collected) e.g. to release some resources acquired during initialization, etc… For this, Smooks provides the @PreDestroy.
The basic initialization/un-initialization sequence can be described as follows:
smooks = new Smooks(..);
// Initialize all annotated components
@PostConstruct
// Use the smooks instance through a series of filterSource invocations...
smooks.filterSource(...);
smooks.filterSource(...);
smooks.filterSource(...);
... etc ...
smooks.close();
// Uninitialize all annotated components
@PreDestroyIn the following example, lets assume we have a component that opens multiple connections to a database on initialization and then needs to release all those database resources when we close the Smooks instance.
public class MultiDataSourceAccessor {
@Inject
private File dataSourceConfig;
Map<String, Datasource> datasources = new HashMap<String, Datasource>();
@PostConstruct
public void createDataSources() {
// Add DS creation code here....
// Read the dataSourceConfig property to read the DS configs...
}
@PreDestroy
public void releaseDataSources() {
// Add DS release code here....
}
// etc...
}Notes:
-
@PostConstructand@PreDestroymethods must be public, zero-arg methods. -
@Injectproperties are all initialized before the first@PostConstructmethod is called. Therefore, you can use@Injectcomponent properties as input to the initialization process. -
@PreDestroymethods are all called in response to a call to theSmooks.closemethod.
Defining Custom Configuration Namespaces
Smooks supports a mechanism for defining custom configuration namespaces for components. This allows you to support custom, XSD based (validatable), configurations for your components Vs treating them all as vanilla Smooks resources via the base configuration.
The basic process involves:
-
Writing an configuration XSD for your component that extends the base https://www.smooks.org/xsd/smooks-2.0.xsd configuration namespace. This XSD must be supplied on the classpath with your component. It must be located in the /META-INF folder and have the same path as the namespace URI. For example, if your extended namespace URI is http://www.acme.com/schemas/smooks/acme-core-1.0.xsd, then the physical XSD file must be supplied on the classpath in "/META-INF/schemas/smooks/acme-core-1.0.xsd".
-
Writing a Smooks configuration namespace mapping configuration file that maps the custom namespace configuration into a
ResourceConfiginstance. This file must be named (by convention) based on the name of the namespace it is mapping and must be physically located on the classpath in the same folder as the XSD. Extending the above example, the Smooks mapping file would be "/META-INF/schemas/smooks/acme-core-1.0.xsd-smooks.xml". Note the "-smooks.xml" postfix.
The easiest way to get familiar with this mechanism is by looking at existing extended namespace configurations within the Smooks code itself. All Smooks components (including e.g. the Java Binding functionality) use this mechanism for defining their configurations. Smooks Core itself defines a number of extended configuration namesaces, as can be seen in the source.
Implementing a Source Reader
Implementing and configuring a new Source Reader for Smooks is straightforward. The Smooks specific parts of the process are easy and are not really the issue. The level of effort involved is a function of the complexity of the Source data format for which you are implementing the reader.
Implementing a Reader for your custom data format immediately opens all Smooks capabilities to that data format e.g. Java Binding, Templating, Persistence, Validation, Splitting & Routing, etc… So a relatively small investment can yield a quite significant return. The only requirement, from a Smooks perspective, is that the Reader implements the standard org.xml.sax.XMLReader interface from the Java JDK. However, if you want to be able to configure the Reader implementation, it needs to implement the org.smooks.api.resource.reader.SmooksXMLReader interface (which is just an extension of org.xml.sax.XMLReader). So, you can easily use (or extend) an existing org.xml.sax.XMLReader implementation, or implement a new Reader from scratch.
Let’s now look at a simple example of implementing a Reader for use with Smooks. In this example, we will implement a Reader that can read a stream of Comma Separated Value (CSV) records, converting the CSV stream into a stream of SAX events that can be processed by Smooks, allowing you to do all the things Smooks allows (Java Binding, etc…).
We start by implementing the basic Reader class:
public class MyCSVReader implements SmooksXMLReader {
// Implement all of the XMLReader methods...
}Two methods from the XMLReader interface are of particular interest:
-
setContentHandler(ContentHandler): This method is called by Smooks Core. It sets the
ContentHandlerinstance for the reader. TheContentHandlerinstance methods are called from inside the parse(InputSource) method. -
parse(InputSource): This is the method that receives the Source data input stream, parses it (i.e. in the case of this example, the CSV stream) and generates the SAX event stream through calls to the
ContentHandlerinstance supplied in thesetContentHandler(ContentHandler)method.
We need to configure our CSV reader with the names of the fields associated with the CSV records. Configuring a custom reader implementation is the same as for any Smooks component, as described in the Configuring Smooks Components section above.
So focusing a little more closely on the above methods and our fields configuration:
public class MyCSVReader implements SmooksXMLReader {
private ContentHandler contentHandler;
@Inject
private String[] fields; // Auto decoded and injected from the "fields" <param> on the reader config.
public void setContentHandler(ContentHandler contentHandler) {
this.contentHandler = contentHandler;
}
public void parse(InputSource csvInputSource) throws IOException, SAXException {
// TODO: Implement parsing of CSV Stream...
}
// Other XMLReader methods...
}So now we have our basic Reader implementation stub. We can start writing unit tests to test the new reader implementation.
First thing we need is some sample CSV input. Lets use a simple list of names:
names.csv
Tom,Fennelly Mike,Fennelly Mark,Jones
Second thing we need is a test Smooks configuration to configure Smooks with our MyCSVReader. As stated before, everything in Smooks is a resource and can be configured with the basic configuration. While this works fine, it’s a little noisy, so Smooks provides a basic configuration element specifically for the purpose of configuring a reader. The configuration for our test looks like the following:
mycsvread-config.xml
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<reader class="com.acme.MyCSVReader">
<params>
<param name="fields">firstname,lastname</param>
</params>
</reader>
</smooks-resource-list>And of course we need the JUnit test class:
public class MyCSVReaderTest extends TestCase {
public void test() {
Smooks smooks = new Smooks(getClass().getResourceAsStream("mycsvread-config.xml"));
StringSink serializedCSVEvents = new StringSink();
smooks.filterSource(new StreamSource(getClass().getResourceAsStream("names.csv")), serializedCSVEvents);
System.out.println(serializedCSVEvents);
// TODO: add assertions, etc...
}
}So now we have a basic setup with our custom Reader implementation, as well as a unit test that we can use to drive our development. Of course, our reader parse method is not doing anything yet and our test class is not making any assertions, etc… So lets start implementing the parse method:
public class MyCSVReader implements SmooksXMLReader {
private ContentHandler contentHandler;
@Inject
private String[] fields; // Auto decoded and injected from the "fields" <param> on the reader config.
public void setContentHandler(ContentHandler contentHandler) {
this.contentHandler = contentHandler;
}
public void parse(InputSource csvInputSource) throws IOException, SAXException {
BufferedReader csvRecordReader = new BufferedReader(csvInputSource.getCharacterStream());
String csvRecord;
// Send the start of message events to the handler...
contentHandler.startDocument();
contentHandler.startElement(XMLConstants.NULL_NS_URI, "message-root", "", new AttributesImpl());
csvRecord = csvRecordReader.readLine();
while(csvRecord != null) {
String[] fieldValues = csvRecord.split(",");
// perform checks...
// Send the events for this record...
contentHandler.startElement(XMLConstants.NULL_NS_URI, "record", "", new AttributesImpl());
for(int i = 0; i < fields.length; i++) {
contentHandler.startElement(XMLConstants.NULL_NS_URI, fields[i], "", new AttributesImpl());
contentHandler.characters(fieldValues[i].toCharArray(), 0, fieldValues[i].length());
contentHandler.endElement(XMLConstants.NULL_NS_URI, fields[i], "");
}
contentHandler.endElement(XMLConstants.NULL_NS_URI, "record", "");
csvRecord = csvRecordReader.readLine();
}
// Send the end of message events to the handler...
contentHandler.endElement(XMLConstants.NULL_NS_URI, "message-root", "");
contentHandler.endDocument();
}
// Other XMLReader methods...
}If you run the unit test class now, you should see the following output on the console (formatted):
<message-root>
<record>
<firstname>Tom</firstname>
<lastname>Fennelly</lastname>
</record>
<record>
<firstname>Mike</firstname>
<lastname>Fennelly</lastname>
</record>
<record>
<firstname>Mark</firstname>
<lastname>Jones</lastname>
</record>
</message-root>After this, it is just a case of expanding the tests, hardening the reader implementation code, etc…
Now you can use your reader to perform all sorts of operations supported by Smooks. As an example, the following configuration could be used to bind the names into a List of PersonName objects:
java-binding-config.xml
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd" xmlns:jb="https://www.smooks.org/xsd/smooks/javabean-1.6.xsd">
<reader class="com.acme.MyCSVReader">
<params>
<param name="fields">firstname,lastname</param>
</params>
</reader>
<jb:bean beanId="peopleNames" class="java.util.ArrayList" createOnElement="message-root">
<jb:wiring beanIdRef="personName" />
</jb:bean>
<jb:bean beanId="personName" class="com.acme.PersonName" createOnElement="message-root/record">
<jb:value property="first" data="record/firstname" />
<jb:value property="last" data="record/lastname" />
</jb:bean>
</smooks-resource-list>And then a test for this configuration could look as follows:
public class MyCSVReaderTest extends TestCase {
public void test_java_binding() {
Smooks smooks = new Smooks(getClass().getResourceAsStream("java-binding-config.xml"));
JavaSink javaSink = new JavaSink();
smooks.filterSource(new StreamSource(getClass().getResourceAsStream("names.csv")), javaSink);
List<PersonName> peopleNames = (List<PersonName>) javaSink.getBean("peopleNames");
// TODO: add assertions etc
}
}For more on Java Binding, see the Java Binding section.
Tips:
-
Reader instances are never used concurrently. Smooks Core will create a new instance for every message, or, will pool and reuse instances as per the readerPoolSize FilterSettings property.
-
If your Reader requires access to the Smooks ExecutionContext for the current filtering context, your Reader needs to implement the
SmooksXMLReaderinterface. -
If your Source data is a binary data stream your Reader must implement the
StreamReaderinterface. See next section. -
You can programmatically configure your reader (e.g. in your unit tests) using a
GenericReaderConfiguratorinstance, which you then set on the Smooks instance. -
While the basic configuration is fine, it’s possible to define a custom configuration namespace (XSD) for your custom CSV Reader implementation. This topic is not covered here. Review the source code to see the extended configuration namespace for the Reader implementations supplied with Smooks (out-of-the-box) e.g. the EDIReader, CSVReader, JSONReader, etc… From this, you should be able to work out how to do this for your own custom Reader.
Implementing a Binary Source Reader
Prior to Smooks v1.5, binary readers needed to implement the StreamReader interface. This is no longer a requirement. All XMLReader instances receive an InputSource (to their parse method) that contains an InputStream if the InputStream was provided in the StreamSource passed in the Smooks.filterSource method call. This means that all XMLReader instance are guaranteed to receive an InputStream if one is available, so no need to mark the XMLReader instance.
Implementing a Flat File Source Reader
In Smooks v1.5 we tried to make it a little easier to implement a custom reader for reading flat file data formats. By flat file we mean "record" based data formats, where the data in the message is structured in flat records as opposed to a more hierarchical structure. Examples of this would be Comma Separated Value (CSV) and Fixed Length Field (FLF). The new API introduced in Smooks v1.5 should remove the complexity of the XMLReader API (as outlined above).
The API is composed of 2 interfaces plus a number of support classes.These interfaces work as a pair. They need to be implemented if you wish to use this API for processing a custom Flat File format not already supported by Smooks.
/**
* {@link RecordParser} factory class.
* <p/>
* Configurable by the Smooks {@link org.smooks.cdr.annotation.Configurator}
*/
public interface RecordParserFactory {
/**
* Create a new Flat File {@link RecordParser} instance.
* @return A new {@link RecordParser} instance.
*/
RecordParser newRecordParser();
}
/**
* Flat file Record Parser.
*/
public interface RecordParser<T extends RecordParserFactory> {
/**
* Set the parser factory that created the parser instance.
* @param factory The parser factory that created the parser instance.
*/
void setRecordParserFactory(T factory);
/**
* Set the Flat File data source on the parser.
* @param source The flat file data source.
*/
void setDataSource(InputSource source);
/**
* Parse the next record from the message stream and produce a {@link Record} instance.
* @return The records instance.
* @throws IOException Error reading message stream.
*/
Record nextRecord() throws IOException;
}Obviously the RecordParserFactory implementation is responsible for creating the RecordParser instances for the Smooks runtime. The RecordParserFactory is the class that Smooks configures, so it is in here you place all your @Inject details. The created RecordParser instances are supplied with a reference to the RecordParserFactory instance that created them, so it is easy enough the provide them with access to the configuration via getters on the RecordParserFactory implementation.
The RecordParser implementation is responsible for parsing out each record (a Record contains a set of Fields) in the nextRecord() method. Each instance is supplied with the Reader to the message stream via the setReader(Reader) method. The RecordParser should store a reference to this Reader and use it in the nextRecord() method. A new instance of a given RecordParser implementation is created for each message being filtered by Smooks.
Configuring your implementation in the Smooks configuration is as simple as the following:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:ff="https://www.smooks.org/xsd/smooks/flatfile-1.6.xsd">
<ff:reader fields="first,second,third" parserFactory="com.acme.ARecordParserFactory">
<params>
<param name="aConfigParameter">aValue</param>
<param name="bConfigParameter">bValue</param>
</params>
</ff:reader>
<!--
Other Smooks configurations e.g. <jb:bean> configurations
-->
</smooks-resource-list>The Flat File configuration also supports basic Java binding configurations, inlined in the reader configuration.
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:ff="https://www.smooks.org/xsd/smooks/flatfile-1.6.xsd">
<ff:reader fields="firstname,lastname,gender,age,country" parserFactory="com.acme.PersonRecordParserFactory">
<!-- The field names must match the property names on the Person class. -->
<ff:listBinding beanId="people" class="com.acme.Person" />
</ff:reader>
</smooks-resource-list>To execute this configuration:
Smooks smooks = new Smooks(configStream);
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(messageReader), sink);
List<Person> people = (List<Person>) sink.getBean("people");Smooks also supports creation of Maps from the record set:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:ff="https://www.smooks.org/xsd/smooks/flatfile-1.6.xsd">
<ff:reader fields="firstname,lastname,gender,age,country" parserFactory="com.acme.PersonRecordParserFactory">
<ff:mapBinding beanId="people" class="com.acme.Person" keyField="firstname" />
</ff:reader>
</smooks-resource-list>The above configuration would produce a Map of Person instances, keyed by the "firstname" value of each Person. It would be executed as follows:
Smooks smooks = new Smooks(configStream);
JavaSink sink = new JavaSink();
smooks.filterSource(new StreamSource(messageReader), sink);
Map<String, Person> people = (Map<String, Person>) sink.getBean("people");
Person tom = people.get("Tom");
Person mike = people.get("Mike");Virtual Models are also supported, so you can define the class attribute as a java.util.Map and have the record field values bound into Map instances, which are in turn added to a List or a Map.
VariableFieldRecordParser and VariableFieldRecordParserFactory
VariableFieldRecordParser and VariableFieldRecordParserFactory are abstract implementations of the RecordParser and RecordParserFactory interface. They provide very useful base implementations for a Flat File Reader, providing base support for:
-
The utility java binding configurations as outlined in the previous section.
-
Support for "variable field" records i.e. a flat file message that contains multiple record definitions. The different records are identified by the value of the first field in the record and are defined as follows:
fields="book[name,author] | magazine[*]". Note the record definitions are pipe separated. "book" records will have a first field value of "book" while "magazine" records will have a first field value of "magazine". Astrix ("*") as the field definition for a record basically tells the reader to generate the field names in the generated events (e.g. "field_0", "field_1", etc…). -
The ability to read the next record chunk, with support for a simple record delimiter, or a regular expression (regex) pattern that marks the beginning of each record.
The CSV and Regex readers are implemented using these abstract classes. See the csv-variable-record and flatfile-to-xml-regex examples. The Regex Reader implementation is also a good example that can be used as a basis for your own custom flat file reader.
Implementing a Fragment Visitor
Visitors are the workhorse of Smooks. Most of the out-of-the-box functionality in Smooks (Java binding, templating, persistence, etc…) was created by creating one or more visitors. Visitors often collaborate through the ExecutionContext and ApplicationContext objects, accomplishing a common goal by working together.
Smooks treats all visitors as stateless objects. A visitor instance must be usable concurrently across multiple messages, that is, across multiple concurrent calls to the Smooks.filterSource method.All state associated with the current Smooks.filterSource execution must be stored in the ExecutionContext. For more details see the ExecutionContext and ApplicationContex section.
|
SAX NG Visitor API
The SAX NG visitor API is made up of a number of interfaces. These interfaces are based on the SAX events that a SaxNgVisitor implementation can capture and processes. Depending on the use case being solved with the SaxNgVisitor implementation, you may need to implement one or all of these interfaces.
BeforeVisitor: Captures the startElement SAX event for the targeted fragment element:
public interface BeforeVisitor extends Visitor {
void visitBefore(Element element, ExecutionContext executionContext);
}ChildrenVisitor: Captures the character based SAX events for the targeted fragment element, as well as Smooks generated (pseudo) events corresponding to the startElement events of child fragment elements:
public interface ChildrenVisitor extends Visitor {
void visitChildText(CharacterData characterData, ExecutionContext executionContext) throws SmooksException, IOException;
void visitChildElement(Element childElement, ExecutionContext executionContext) throws SmooksException, IOException;
}AfterVisitor: Captures the endElement SAX event for the targeted fragment element:
public interface AfterVisitor extends Visitor {
void visitAfter(Element element, ExecutionContext executionContext);
}As a convenience for those implementations that need to capture all the SAX events, the above three interfaces are pulled together into a single interface in the ElementVisitor interface.
Illustrating these events using a piece of XML:
<message>
<target-fragment> <--- BeforeVisitor.visitBefore
Text!! <--- ChildrenVisitor.visitChildText
<child> <--- ChildrenVisitor.visitChildElement
</child>
</target-fragment> <--- AfterVisitor.visitAfter
</message>| Of course, the above is just an illustration of a Source message event stream and it looks like XML, but could be EDI, CSV, JSON, etc… Think of this as just an XML serialization of a Source message event stream, serialized as XML for easy reading. |
Element: As can be seen from the above SAX NG interfaces, Element type is passed in all method calls. This object contains details about the targeted fragment element, including attributes and their values. We’ll discuss text accumulation and StreamSink writing in the coming sections.
Text Accumulation
SAX is a stream based processing model. It doesn’t create a Document Object Model (DOM) of any form. It doesn’t "accumulate" event data in any way. This is why it is a suitable processing model for processing huge message streams.
The Element will always contain attributes associated with the targeted element, but will not contain the fragment child text data, whose SAX events (ChildrenVisitor.visitChildText) occur between the BeforeVisitor.visitBefore and AfterVisitor.visitAfter events (see above illustration). The filter does not accumulate text events on the Element because, as already stated, that could result in a significant performance drain. Of course the downside to this is the fact that if your SaxNgVisitor implementation needs access to the text content of a fragment, you need to explicitly tell Smooks to accumulate text for the targeted fragment. This is done by stashing the text into a memento from within the ChildrenVisitor.visitChildText method and then restoring the memento from within the AfterVisitor.visitAfter method implementation of your SaxNgVisitor as shown below:
public class MyVisitor implements ChildrenVisitor, AfterVisitor {
@Override
public void visitChildText(CharacterData characterData, ExecutionContext executionContext) {
executionContext.getMementoCaretaker().stash(new TextAccumulatorMemento(new NodeVisitable(characterData.getParentNode()), this), textAccumulatorMemento -> textAccumulatorMemento.accumulateText(characterData.getTextContent()));
}
@Override
public void visitChildElement(Element childElement, ExecutionContext executionContext) {
}
@Override
public void visitAfter(Element element, ExecutionContext executionContext) {
TextAccumulatorMemento textAccumulatorMemento = new TextAccumulatorMemento(new NodeVisitable(element), this);
executionContext.getMementoCaretaker().restore(textAccumulatorMemento);
String fragmentText = textAccumulatorMemento.getTextContent();
// ... etc ...
}
}It is a bit ugly having to implement ChildrenVisitor.visitChildText just to tell Smooks to accumulate the text events for the targeted fragment. For that reason, we have the @TextConsumer annotation that can be used to annotate your SaxNgVisitor implementation, removing the need to implement the ChildrenVisitor.visitChildText method:
@TextConsumer
public class MyVisitor implements AfterVisitor {
public void visitAfter(Element element, ExecutionContext executionContext) {
String fragmentText = element.getTextContent();
// ... etc ...
}
}Note that the complete fragment text will not be available until the AfterVisitor.visitAfter event.
StreamSink Writing/Serialization
The Smooks.filterSource(Source, Sink) method can take one or more of a number of different Sink type implementations, one of which is the StreamSink class (see Multiple results/sinks). By default, Smooks will always serialize the full Source event stream as XML to any StreamSink instance provided to the Smooks.filterSource(Source, Sink) method.
So, if the Source provided to the Smooks.filterSource(Source, Sink) method is an XML stream and a StreamSink instance is provided as one of the Sink instances, the Source XML will be written out to the
StreamSink unmodified, unless the Smooks instance is configured with one or more SaxNgVisitor implementations that modify one or more fragments. In other words, Smooks streams the Source in and back out again through the StreamSink instance. Default serialization can be turned on/off by configuring the filter settings.
If you want to modify the serialized form of one of the message fragments (i.e. "transform"), you need to implement a SaxNgVisitor to do so and target it at the message fragment using an XPath-like expression.
Of course, you can also modify the serialized form of a message fragment using one of the out-of-the-box Templating components. These components are also SaxNgVisitor implementations.
|
The key to implementing a SaxNgVisitor geared towards transforming the serialized form of a fragment is telling Smooks that the SaxNgVisitor implementation in question will be writing to the StreamSink. You need to tell Smooks this because Smooks supports targeting of multiple SaxNgVisitor implementations at a single fragment, but only one SaxNgVisitor is allowed to write to the StreamSink, per fragment. If a second SaxNgVisitor attempts to write to the StreamSink, a SAXWriterAccessException will result and you will need to modify your Smooks configuration.
In order to be "the one" that writes to the StreamSink, the SaxNgVisitor needs to acquire ownership of the Writer to the StreamSink. It does this by simply making a call to the ExecutionContext.getWriter().write(…) method from inside the BeforeVisitor.visitBefore methods implementation:
public class MyVisitor implements ElementVisitor {
@Override
public void visitBefore(Element element, ExecutionContext executionContext) {
Writer writer = executionContext.getWriter();
// ... write the start of the fragment...
}
@Override
public void visitChildText(CharacterData characterData, ExecutionContext executionContext) {
Writer writer = executionContext.getWriter();
// ... write the child text...
}
@Override
public void visitChildElement(Element childElement, ExecutionContext executionContext) {
}
@Override
public void visitAfter(Element element, ExecutionContext executionContext) {
Writer writer = executionContext.getWriter();
// ... close the fragment...
}
}
If you need to control serialization of sub-fragments you need to reset the Writer instance so as to divert serialization of the sub-fragments. You do this by calling ExecutionContext.setWriter.
|
Sometimes you know that the target fragment you are serializing/transforming will never have sub-fragments. In this situation, it’s a bit ugly to have to implement the BeforeVisitor.visitBefore method just to make a call to the ExecutionContext.getWriter().write(...) method to acquire ownership of the Writer. For this reason, we have the @StreamSinkWriter annotation. Used in combination with the @TextConsumer annotation, we can remove the need to implement all but the AfterVisitor.visitAfter method:
@TextConsumer
@StreamSinkWriter
public class MyVisitor implements AfterVisitor {
public void visitAfter(Element element, ExecutionContext executionContext) {
Writer writer = executionContext.getWriter();
// ... serialize to the writer ...
}
}DomSerializer
Smooks provides the DomSerializer class to make serializing of element data, as XML, a little easier. This class allows you to write a SaxNgVisitor implementation like:
@StreamSinkWriter
public class MyVisitor implements ElementVisitor {
private DomSerializer domSerializer = new DomSerializer(true, true);
@Override
public void visitBefore(Element element, ExecutionContext executionContext) {
try {
domSerializer.writeStartElement(element, executionContext.getWriter());
} catch (IOException e) {
throw new SmooksException(e);
}
}
@Override
public void visitChildText(CharacterData characterData, ExecutionContext executionContext) {
try {
domSerializer.writeText(characterData, executionContext.getWriter());
} catch (IOException e) {
throw new SmooksException(e);
}
}
@Override
public void visitChildElement(Element element, ExecutionContext executionContext) throws SmooksException, IOException {
}
@Override
public void visitAfter(Element element, ExecutionContext executionContext) throws SmooksException, IOException {
try {
domSerializer.writeEndElement(element, executionContext.getWriter());
} catch (IOException e) {
throw new SmooksException(e);
}
}
}You may have noticed that the arguments in the DomSerializer constructor are boolean. This is the closeEmptyElements and rewriteEntities args which should be based on the closeEmptyElements and rewriteEntities filter setting, respectively. Smooks provides a small code optimization/assist here. If you annotate the DomSerializer field with @Inject, Smooks will create the DomSerializer instance and initialize it with the closeEmptyElements and rewriteEntities filter settings for the associated Smooks instance:
@TextConsumer
public class MyVisitor implements AfterVisitor {
@Inject
private DomSerializer domSerializer;
public void visitAfter(Element element, ExecutionContext executionContext) throws SmooksException, IOException {
try {
domSerializer.writeStartElement(element, executionContext.getWriter());
domSerializer.writeText(element, executionContext.getWriter());
domSerializer.writeEndElement(element, executionContext.getWriter());
} catch (IOException e) {
throw new SmooksException(e);
}
}
}Visitor Configuration
SaxNgVisitor configuration works in exactly the same way as any other Smooks component. See Configuring Smooks Components.
The most important thing to note with respect to configuring visitor instances is the fact that the selector attribute is interpreted as an XPath (like) expression. For more on this see the docs on Selectors.
Also note that visitors can be programmatically configured on a Smooks instance. Among other things, this is very useful for unit testing.
Example Visitor Configuration
Let’s assume we have a very simple SaxNgVisitor implementation as follows:
@TextConsumer
public class ChangeItemState implements AfterVisitor {
@Inject
private DomSerializer domSerializer;
@Inject
private String newState;
public void visitAfter(Element element, ExecutionContext executionContext) {
element.setAttribute("state", newState);
try {
domSerializer.writeStartElement(element, executionContext.getWriter());
domSerializer.writeText(element, executionContext.getWriter());
domSerializer.writeEndElement(element, executionContext.getWriter());
} catch (IOException e) {
throw new SmooksException(e);
}
}
}Declaratively configuring ChangeItemState to fire on fragments having a status of "OK" is as simple as:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd">
<resource-config selector="order-items/order-item[@status = 'OK']">
<resource>com.acme.ChangeItemState </resource>
<param name="newState">COMPLETED</param>
</resource-config>
</smooks-resource-list>Of course it would be really nice to be able to define a cleaner and more strongly typed configuration for the ChangeItemState component, such that it could be configured something like:
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:order="http://www.acme.com/schemas/smooks/order.xsd">
<order:changeItemState itemElement="order-items/order-item[@status = 'OK']" newState="COMPLETED" />
</smooks-resource-list>For details on this, see the section on Defining Custom Configuration Namespaces.
This visitor could also be programmatically configured on a Smooks as follows:
Smooks smooks = new Smooks();
smooks.addVisitor(new ChangeItemState().setNewState("COMPLETED"), "order-items/order-item[@status = 'OK']");
smooks.filterSource(new StreamSource(inReader), new StreamSink(outWriter));Visitor Instance Lifecycle
One aspect of the visitor lifecycle has already been discussed in the general context of Smooks component initialization and un-initialization.
Smooks supports two additional component lifecycle events, specific to visitor components, via the PostExecutionLifecycle and PostFragmentLifecycle interfaces.
PostExecutionLifecycle
Visitor components implementing this lifecycle interface will be able to perform post Smooks.filterSource lifecycle operations.
public interface PostExecutionLifecycle {
void onPostExecution(ExecutionContext executionContext);
}The basic call sequence can be described as follows (note the onPostExecution calls):
smooks = new Smooks(..);
smooks.filterSource(...);
** VisitorXX.onPostExecution **
smooks.filterSource(...);
** VisitorXX.onPostExecution **
smooks.filterSource(...);
** VisitorXX.onPostExecution **
... etc ...This lifecycle method allows you to ensure that resources scoped around the Smooks.filterSource execution lifecycle can be cleaned up for the associated ExecutionContext.
PostFragmentLifecycle
Visitor components implementing this lifecycle interface will be able to perform post AfterVisitor.visitAfter lifecycle operations.
public interface PostFragmentLifecycle extends Visitor {
void onPostFragment(Fragment<?> fragment, ExecutionContext executionContext);
}The basic call sequence can be described as follows (note the onPostFragment calls):
smooks.filterSource(...);
<message>
<target-fragment> <--- VisitorXX.visitBefore
Text!! <--- VisitorXX.visitChildText
<child> <--- VisitorXX.visitChildElement
</child>
</target-fragment> <--- VisitorXX.visitAfter
** VisitorXX.onPostFragment **
<target-fragment> <--- VisitorXX.visitBefore
Text!! <--- VisitorXX.visitChildText
<child> <--- VisitorXX.visitChildElement
</child>
</target-fragment> <--- VisitorXX.visitAfter
** VisitorXX.onPostFragment **
</message>
VisitorXX.onPostExecution
smooks.filterSource(...);
<message>
<target-fragment> <--- VisitorXX.visitBefore
Text!! <--- VisitorXX.visitChildText
<child> <--- VisitorXX.visitChildElement
</child>
</target-fragment> <--- VisitorXX.visitAfter
** VisitorXX.onPostFragment **
<target-fragment> <--- VisitorXX.visitBefore
Text!! <--- VisitorXX.visitChildText
<child> <--- VisitorXX.visitChildElement
</child>
</target-fragment> <--- VisitorXX.visitAfter
** VisitorXX.onPostFragment **
</message>
VisitorXX.onPostExecution
This lifecycle method allows you to ensure that resources scoped around a single fragment execution of a SaxNgVisitor implementation can be cleaned up for the associated ExecutionContext.
ExecutionContext
ExecutionContext is scoped specifically around a single execution of a Smooks.filterSource method. All Smooks visitors must be stateless within the context of a single execution. A visitor
is created once in Smooks and referenced across multiple concurrent executions of the Smooks.filterSource method. All data stored in an ExecutionContext instance will be lost on completion of the Smooks.filterSource execution. ExecutionContext is a parameter in all visit invocations.
ApplicationContext
ApplicationContext is scoped around the associated Smooks instance: only one ApplicationContext instance exists per Smooks instance. This context object can be used to store data that needs to be maintained (and accessible) across multiple Smooks.filterSource executions. Components (any component, including SaxNgVisitor components) can gain access to their associated ApplicationContext instance by declaring an ApplicationContext class property and annotating it with @Inject:
public class MySmooksResource {
@Inject
private ApplicationContext appContext;
// etc...
}Instrumentation
| Smooks instrumentation is available starting from v2.0.0-RC4. |
A Smooks application can be instrumented with JMX which allows IT operations to monitor and manage Smooks from tools such as JConsole, Grafana, and NewRelic. Apart from the MBeans provided by the Java runtime and third-party libraries, Smooks provides MBeans for:
-
resources (e.g., resource config parameters)
-
visitors (e.g., performance metrics, failure visit count, events visited)
-
reader pools (e.g., no. of active readers)
Activation
To activate instrumentation in Smooks, you need to:
-
Add the
smooks-managementmodule to your Java class path. The Maven coordinates for this module are:<dependency> <groupId>org.smooks</groupId> <artifactId>smooks-management</artifactId> <version>2.1.0</version> </dependency> -
Declare
management:instrumentationResourcein the Smooks config to activate instrumentation:<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd" xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd" xmlns:management="https://www.smooks.org/xsd/smooks/management-1.0.xsd"> <management:instrumentationResource/> ... ... </smooks-resource-list>management:instrumentationResourcesupports the following attributes:Name Description Default usePlatformMBeanServer
Whether to use the MBeanServer from this JVM.
true
mBeanServerDefaultDomain
The default JMX domain of the MBeanServer.
org.smooks
mBeanObjectDomainName
The JMX domain that all object names will use.
org.smooks
includeHostName
Whether to include the hostname in the MBean naming.
false
-
Optionally, declare the
org.smooks.management.InstrumentationInterceptorinterceptor to instrument visitors:<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd" xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd" xmlns:management="https://www.smooks.org/xsd/smooks/management-1.0.xsd"> <management:instrumentationResource/> <core:interceptors> <core:interceptor class="org.smooks.management.InstrumentationInterceptor"/> </core:interceptors> ... ... </smooks-resource-list>
Extending
In addition to the Smooks classes that are already instrumented, you can instrument your own classes with the help of annotations located in the org.smooks.management.annotation package which are listed below:
@ManagedResource
Annotating a class with org.smooks.management.annotation.ManagedResource effectively turns the class into an MBean which allows an instance of the class to be registered with an MBean server. Here is an example of a class annotated with @ManagedResource:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
...
...
import org.smooks.api.ApplicationContext;
import org.smooks.api.management.InstrumentationAgent;
import org.smooks.api.management.InstrumentationResource;
import org.smooks.management.annotation.ManagedResource;
import javax.management.ObjectName;
@ManagedResource(description = "My Class")
public class MyManagedClass {
public MyManagedClass(ApplicationContext applicationContext) {
InstrumentationResource instrumentationResource = applicationContext.getRegistry().lookup(InstrumentationResource.INSTRUMENTATION_RESOURCE_TYPED_KEY);
InstrumentationAgent instrumentationAgent = instrumentationResource.getInstrumentationAgent();
instrumentationAgent.register(this, new ObjectName("org.smooks:type=app,name=MyClass"));
}
...
...
}
Line 17 from the snippet above uses InstrumentationAgent to register the @ManagedResource annotated object with the MBean server so that it can be queried and invoked by JMX clients. InstrumentationAgent is obtained from an instance of org.smooks.api.management.InstrumentationResource. The singleton InstrumentationResource can be looked up from the Smooks registry as shown in line 14.
Instrumentation needs to be activated in order to obtain a non-null InstrumentationResource from the lookup.
|
@ManagedAttribute
Annotating a method with org.smooks.management.annotation.ManagedAttribute exposes the method as an MBean attribute. Here is an example of a method annotated with @ManagedAttribute:
...
...
import org.smooks.management.annotation.ManagedAnnotation;
import org.smooks.management.annotation.ManagedResource;
@ManagedResource
public class MyManagedClass {
private String myAttribute;
...
...
@ManagedAttribute(description = "My attribute")
public String getMyAttribute() {
return myAttribute;
}
}@ManagedOperation
Annotating a method with org.smooks.management.annotation.ManagedOperation exposes the method and its parameters as an MBean operation. Here is an example of a method annotated with @ManagedOperation:
...
...
import org.smooks.management.annotation.ManagedOperation;
import org.smooks.management.annotation.ManagedResource;
@ManagedResource
public class MyManagedClass {
...
...
@ManagedOperation(description = "My operation")
public void myOperation(String myFirstParam, Integer mySecondParam) {
...
...
}
}@ManagedNotification
Annotating a class with org.smooks.management.annotation.ManagedNotification allows JMX clients to subscribe to notifications broadcasted from instances of this class. Here is an example of a method annotated with @ManagedNotification:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
...
...
import org.smooks.api.ApplicationContext;
import org.smooks.api.management.InstrumentationAgent;
import org.smooks.api.management.InstrumentationResource;
import org.smooks.management.ModelMBeanAssembler;
import org.smooks.management.annotation.ManagedNotification;
import org.smooks.management.annotation.ManagedResource;
import javax.management.MBeanException;
import javax.management.Notification;
import javax.management.ObjectName;
import javax.management.modelmbean.ModelMBeanInfo;
import javax.management.modelmbean.RequiredModelMBean;
import java.util.concurrent.atomic.AtomicLong;
@ManagedResource
@ManagedNotification(name = "My Notification", notificationTypes = {"javax.management.Notification"})
public class MyManagedClass {
private final RequiredModelMBean requiredModelMBean;
private final AtomicLong sequenceNumber = new AtomicLong();
public MyManagedClass(ApplicationContext applicationContext) {
InstrumentationResource instrumentationResource = applicationContext.getRegistry().lookup(InstrumentationResource.INSTRUMENTATION_RESOURCE_TYPED_KEY);
InstrumentationAgent instrumentationAgent = instrumentationResource.getInstrumentationAgent();
ModelMBeanAssembler modelMBeanAssembler = new ModelMBeanAssembler();
ModelMBeanInfo modelMBeanInfo = modelMBeanAssembler.getModelMbeanInfo(this.getClass());
requiredModelMBean = instrumentationAgent.register(this, new ObjectName("org.smooks:type=app,name=MyClass"), modelMBeanInfo, false);
}
public void sendNotification(String message) throws MBeanException {
Notification notification = new Notification("My Notification", requiredModelMBean, sequenceNumber.addAndGet(1), message);
requiredModelMBean.sendNotification(message);
}
}
As illustrated above in lines 29-30, to register a @ManagedNotification instance, the MBean descriptor should be assembled dynamically with org.smooks.management.ModelMBeanAssembler. The assembled javax.management.modelmbean.ModelMBeanInfo is then registered using InstrumentationAgent as shown in line 31. InstrumentationAgent.register(Object, ObjectName, ModelMBeanInfo, boolean) returns a RequiredModelMBean object that can be referenced to broadcast notifications, seen in lines 35-36.
@ManagedNotifications
Adding more than one notification type can be achieved with org.smooks.management.annotation.ManagedNotifications. Here is an example of a method annotated with @ManagedNotifications:
...
...
import org.smooks.api.ApplicationContext;
import org.smooks.api.management.InstrumentationAgent;
import org.smooks.api.management.InstrumentationResource;
import org.smooks.management.ModelMBeanAssembler;
import org.smooks.management.annotation.ManagedNotification;
import org.smooks.management.annotation.ManagedNotifications;
import org.smooks.management.annotation.ManagedResource;
import javax.management.MBeanException;
import javax.management.Notification;
import javax.management.ObjectName;
import javax.management.modelmbean.ModelMBeanInfo;
import javax.management.modelmbean.RequiredModelMBean;
import java.util.concurrent.atomic.AtomicLong;
@ManagedResource
@ManagedNotifications(value = {@ManagedNotification(name = "My Notification", notificationTypes = {"javax.management.Notification"}),
@ManagedNotification(name = "Another Notification", notificationTypes = {"javax.management.Notification"})})
public class MyManagedClass {
private final RequiredModelMBean requiredModelMBean;
private final AtomicLong sequenceNumber = new AtomicLong();
public MyManagedClass(ApplicationContext applicationContext) {
InstrumentationResource instrumentationResource = applicationContext.getRegistry().lookup(InstrumentationResource.INSTRUMENTATION_RESOURCE_TYPED_KEY);
InstrumentationAgent instrumentationAgent = instrumentationResource.getInstrumentationAgent();
ModelMBeanAssembler modelMBeanAssembler = new ModelMBeanAssembler();
ModelMBeanInfo modelMBeanInfo = modelMBeanAssembler.getModelMbeanInfo(this.getClass());
requiredModelMBean = instrumentationAgent.register(this, new ObjectName("org.smooks:type=app,name=MyClass"), modelMBeanInfo, false);
}
public void sendMyNotification(String message) throws MBeanException {
Notification notification = new Notification("My Notification", requiredModelMBean, sequenceNumber.addAndGet(1), message);
requiredModelMBean.sendNotification(message);
}
public void sendAnotherNotification(String message) throws MBeanException {
Notification notification = new Notification("Another Notification", requiredModelMBean, sequenceNumber.addAndGet(1), message);
requiredModelMBean.sendNotification(message);
}
}Common use cases
Processing Huge Messages (GBs)
One of the main features introduced in Smooks v1.0 is the ability to process huge messages (Gbs in size). Smooks supports the following types of processing for huge messages:
-
One-to-One Transformation: This is the process of transforming a huge message from its source format (e.g. XML), to a huge message in a target format e.g. EDI, CSV, XML etc.
-
Splitting & Routing: Splitting of a huge message into smaller (more consumable) messages in any format (EDI, XML, Java, etc…) and Routing of those smaller messages to a number of different destination types (filesystem, JMS, database).
-
Persistence: Persisting the components of the huge message to a database, from where they can be more easily queried and processed. Within Smooks, we consider this to be a form of Splitting and Routing (routing to a database).
All of the above is possible without writing any code (i.e. in a declarative manner). Typically, any of the above types of processing would have required writing quite a bit of ugly/unmaintainable code. It might also have been implemented as a multi-stage process where the huge message is split into smaller messages (stage #1) and then each smaller message is processed in turn to persist, route, etc… (stage #2). This would all be done in an effort to make that ugly/unmaintainable code a little more maintainable and reusable. With Smooks, most of these use-cases can be handled without writing any code. As well as that, they can also be handled in a single pass over the source message, splitting and routing in parallel (plus routing to multiple destinations of different types and in different formats).
| Be sure to read the section on Java Binding. |
One-to-One Transformation
If the requirement is to process a huge message by transforming it into a single message of another format, the easiest mechanism with Smooks is to apply multiple FreeMarker templates to the Source message Event Stream, outputting to a Smooks.filterSource sink stream.
This can be done in one of 2 ways with FreeMarker templating, depending on the type of model that’s appropriate:
-
Using FreeMarker + NodeModels for the model.
-
Using FreeMarker + a Java Object model for the model. The model can be constructed from data in the message, using the Javabean Cartridge.
Option #1 above is obviously the option of choice, if the tradeoffs are OK for your use case. Please see the FreeMarker Templating docs for more details.
The following images shows an message, as well as the message to which we need to transform the message:

Imagine a situation where the message contains millions of elements. Processing a huge message in this way with Smooks and FreeMarker (using NodeModels) is quite straightforward. Because the message is huge, we need to identify multiple NodeModels in the message, such that the runtime memory footprint is as low as possible. We cannot process the message using a single model, as the full message is just too big to hold in memory. In the case of the message, there are 2 models, one for the main data (blue highlight) and one for the data (beige highlight):

So in this case, the most data that will be in memory at any one time is the main order data, plus one of the order-items. Because the NodeModels are nested, Smooks makes sure that the order data NodeModel never contains any of the data from the order-item NodeModels. Also, as Smooks filters the message, the order-item NodeModel will be overwritten for every order-item (i.e. they are not collected). See SAX NG.
Configuring Smooks to capture multiple NodeModels for use by the FreeMarker templates is just a matter of configuring the DomModelCreator visitor, targeting it at the root node of each of the models. Note again that Smooks also makes this available to SAX filtering (the key to processing huge message). The Smooks configuration for creating the NodeModels for this message are:
<?xml version="1.0"?>
<smooks-resource-list xmlns="https://www.smooks.org/xsd/smooks-2.0.xsd"
xmlns:core="https://www.smooks.org/xsd/smooks/smooks-core-1.6.xsd"
xmlns:ftl="https://www.smooks.org/xsd/smooks/freemarker-2.0.xsd">
<!--
Create 2 NodeModels. One high level model for the "order"
(header, etc...) and then one for the "order-item" elements...
-->
<resource-config selector="order,order-item">
<resource>org.smooks.engine.resource.visitor.dom.DomModelCreator</resource>
</resource-config>
<!-- FreeMarker templating configs to be added below... -->Now the FreeMarker templates need to be added. We need to apply 3 templates in total:
-
A template to output the order "header" details, up to but not including the order items.
-
A template for each of the order items, to generate the elements in the .
-
A template to close out the message.
With Smooks, we implement this by defining 2 FreeMarker templates. One to cover #1 and #3 (combined) above, and a seconds to cover the elements.
The first FreeMarker template is targeted at the element and looks as follows:
<ftl:freemarker applyOnElement="order-items">
<ftl:template><!--<salesorder>
<details>
<orderid>${order.@id}</orderid>
<customer>
<id>${order.header.customer.@number}</id>
<name>${order.header.customer}</name>
</customer>
</details>
<itemList>
<?TEMPLATE-SPLIT-PI?>
</itemList>
</salesorder>-->
</ftl:template>
</ftl:freemarker>You will notice the `<?TEMPLATE-SPLIT-PI?>` processing instruction. This tells Smooks where to split the template, outputting the first part of the template at the start of the element, and the other part at the end of the element. The element template (the second template) will be output in between.
The second FreeMarker template is very straightforward. It simply outputs the elements at the end of every element in the source message:
<ftl:freemarker applyOnElement="order-item">
<ftl:template><!-- <item>
<id>${.vars["order-item"].@id}</id>
<productId>${.vars["order-item"].product}</productId>
<quantity>${.vars["order-item"].quantity}</quantity>
<price>${.vars["order-item"].price}</price>
</item>-->
</ftl:template>
</ftl:freemarker>
</smooks-resource-list>Because the second template fires on the end of the elements, it effectively generates output into the location of the <?TEMPLATE-SPLIT-PI?> Processing Instruction in the first template. Note that the second template could have also referenced data in the "order" NodeModel.
And that’s it! This is available as a runnable example in the Tutorials section.
This approach to performing a One-to-One Transformation of a huge message works simply because the only objects in memory at any one time are the order header details and the current details (in the Virtual Object Model).? Obviously it can’t work if the transformation is so obscure as to always require full access to all the data in the source message e.g. if the messages needs to have all the order items reversed in order (or sorted).? In such a case however, you do have the option of routing the order details and items to a database and then using the database’s storage, query and paging features to perform the transformation.
Splitting & Routing
Smooks supports a number of options when it comes to splitting and routing fragments. The ability to split the stream into fragments and route these fragments to different endpoints (File, JMS, etc…) is a fundamental capability. Smooks improves this capability with the following features:
-
Basic Fragment Splitting: basic splitting means that no fragment transformation happens prior to routing. Basic splitting and routing involves defining the XPath of the fragment to be split out and defining a routing component (e.g., Apache Camel) to route that unmodified split fragment.
-
Complex Fragment Splitting: basic fragment splitting works for many use cases and is what most splitting and routing solutions offer. Smooks extends the basic splitting capabilities by allowing you to perform transformations on the split fragment data before routing is applied. For example, merging in the customer-details order information with each order-item information before performing the routing order-item split fragment routing.
-
In-Flight Stream Splitting & Routing (Huge Message Support): Smooks is able to process gigabyte streams because it can perform in-flight event routing; events are not accumulated when the
max.node.depthparameter is left unset. -
Multiple Splitting and Routing: conditionally split and route multiple fragments (different formats XML, EDI, POJOs, etc…) to different endpoints in a single filtering pass of the source. One could route an OrderItem Java instance to the HighValueOrdersValidation JMS queue for order items with a value greater than $1,000 and route all order items as XML/JSON to an HTTP endpoint for logging. :imagesdir: